
多数人不判断 agent,只是在吸收它的结论
多数人不判断 agent,只是在吸收它的结论
你让 agent 修一个 bug,三十秒它把 PR 甩了回来,描述写得头头是道,测试看着也跑过了。你扫一眼,觉得”应该没问题”,合并。
越来越多的活是这么交出去的。agent 产出越快,你真正焦虑的就越不是它写得对不对,而是另一个问题:我凭什么判断该不该信它?
我们默认这种判断力是天赋。有人就是一眼能看出一段代码好不好,一个方案靠不靠谱;有人不行,那是没天分。AI 时代这个焦虑被放大了——它一屏接一屏地给你东西,你要么逐行较真(来不及),要么扫一眼觉得”好像没问题”(那不叫判断)。
最近读到一篇讲科研的文章,里面一句话把这事说穿了:taste 不是天赋(gift),是肌肉(muscle)。 它甚至给了练法。这套练法,搬到和 agent 协作上,严丝合缝。
判断力的练法:预测,然后对账
那篇文章讲怎么训练科研品味,方法朴素得不像方法:每次实验之前,先预测它的结果。把一篇论文的结果部分盖住,只看方法,自己先猜出那些数字。给本月的每个新发布打个赌——两年后它还重不重要——过段时间回头核自己的命中率。
一次预测加一次修正,重复几百次,是任何一个好模型被训练出来的方式,包括你脑子里那台。
把”实验”换成”agent 的输出”,这套就是判断力的练法。
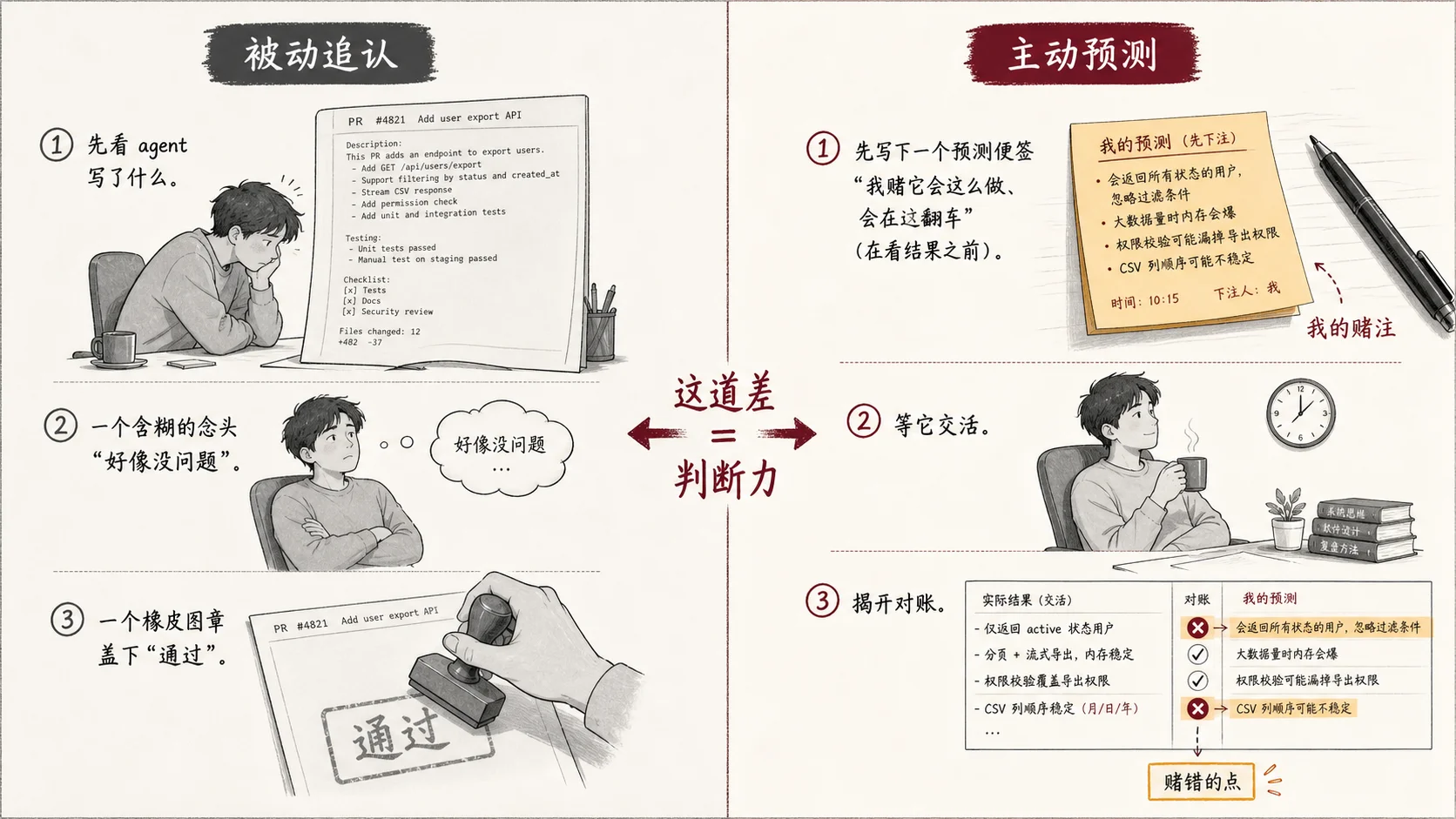
你之所以判断不了 agent 给你的东西,往往是因为你的顺序错了:你先看它写了什么,再回头觉得”嗯好像没问题”。这不是判断,是追认——结论已经摆在你面前,你只是给它盖了个章。真正的判断发生在你看到答案之前。
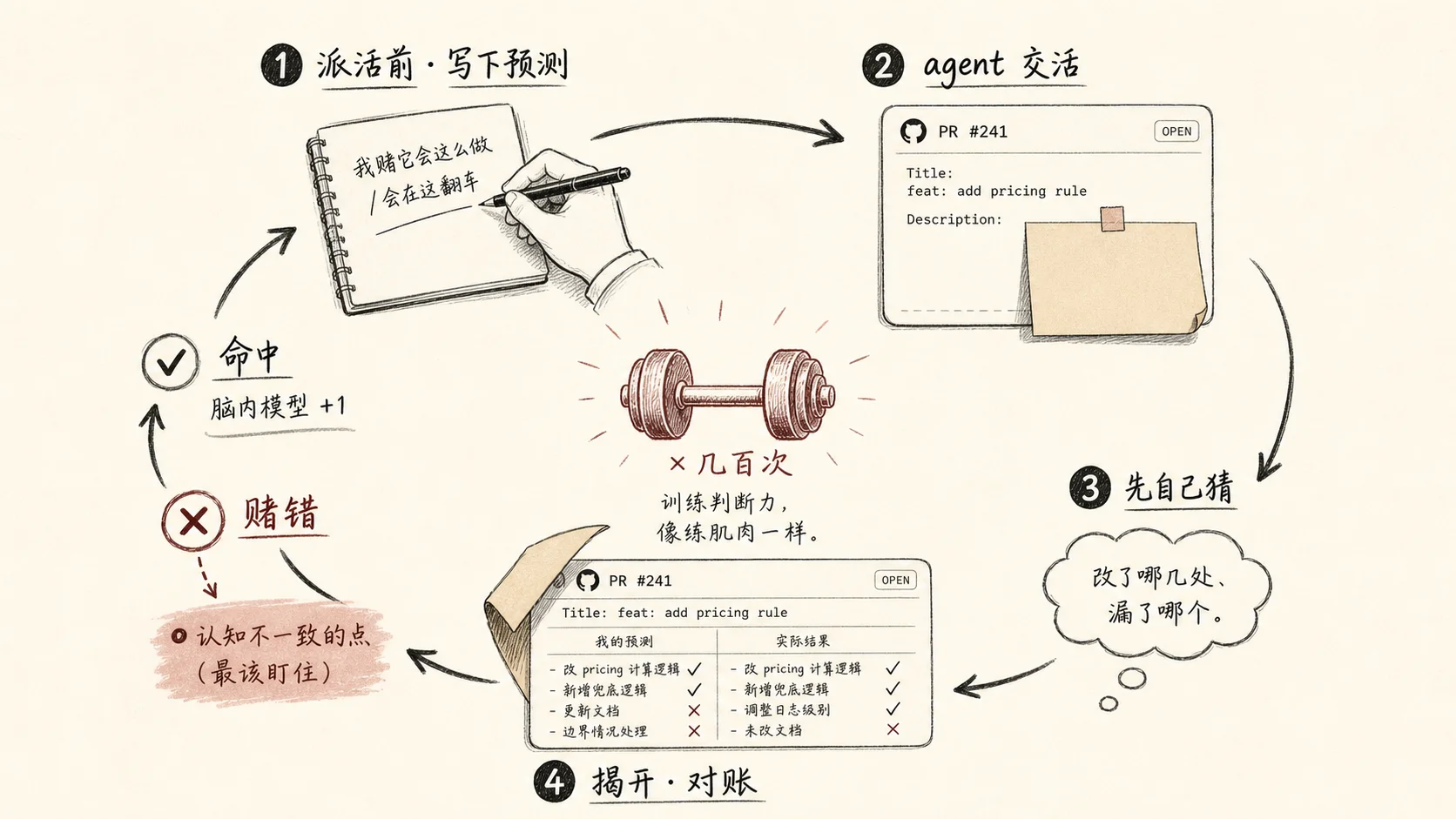
派活之前,先写下你赌它会怎么做
具体到动作,就一句:派活之前,先写下你赌它会怎么做。
让 agent 实现一个功能前,先写一句:我赌它会用这个方案、会在这个边界上翻车。让它改一个 bug 前,先写:我赌根因在这里。等它把 PR 甩回来,先别看它的描述——盖住,自己先猜它改了哪几个地方、漏了哪个。然后对账。
赌对了,你的脑内模型得到一次确认;赌错了,你恰好抓住了一个你和它认知不一致的点——那个点,就是这段代码最该被你盯住的地方。
这件事的成本低到可笑,几乎只是动笔写一句话。但它把你从”被动追认”扳回”主动预测”,而追认和预测之间的差,就是判断力本身。
为什么大多数人练不出来
那篇文章里还有个让我印象很深的细节。Hamming 在贝尔实验室有个习惯,搞得他午饭桌上不太受欢迎:他会问邻座,你们领域最重要的问题是什么;然后问,那你为什么不做那个?人们换桌子坐。
这个问题刺人,是因为多数人答不上来。我们不选问题,我们吸收问题——从导师那、从某个大厂上季度宣布了什么、从这周大家都在转的那篇论文。吸收来的问题,你握着结论,却没有推导:你知道某个著名实验室在乎某个方向,但不知道为什么,不知道他们期待找到什么,也不知道什么会让他们放弃它。
对 agent 也一样。多数人不判断 agent,只是吸收 agent 的结论——它给的方案看着挺像回事,那就用吧。你握着它的产出,却没有自己的预测去跟它对账。一旦它跑偏,你和大多数人一样,一年后才发现。
落点
判断力不是你天生有没有那双眼睛,是你敢不敢在看到答案之前,先押一个预测下去。
下次把活交给 agent,在敲回车之前,先花十秒写一句:我赌它会这么做,会在这里出问题。然后等它交活,对账。
几百次之后,那台脑内模型就练出来了。这事没有天赋这一说,只有你做没做那次预测。