
Spec 里最危险的,是你觉得不用写的部分
Spec 里最危险的,是你觉得不用写的部分
上个月我在给自己做的一个工具加缓存。
这个工具对接了一个数据平台,查得多,偶尔也会通过它去更新数据。查询响应慢,重复查又多,加个本地缓存是顺理成章的事。我给 Codex 写了一份 Spec:背景交代了查询慢的原因,目标是常用查询命中缓存、响应从 800ms 降到 100ms 以内。非目标也划了:不做持久化,不做分布式。约束写了缓存失效时间 5 分钟,验收标准精确到命中时响应低于 50ms。
AI 交回来的代码结构清楚。本地内存缓存,LRU 淘汰,5 分钟过期,测试全绿。我合并了。
用了两三天,我发现一个问题:通过工具改了一条数据,改完立刻查,结果还是旧的。刷新了几次没变,等了几分钟才过来。
我去看代码。AI 只给查询路径加了缓存,更新路径完全没碰。数据改了,缓存不知道,还在返回旧值。读和写在同一个代码库里,AI 没有把它们关联起来。
我回头看 Spec,写了”缓存失效时间 5 分钟”,没写”更新数据时清除对应缓存”。我没写,因为在我做过的每一个缓存系统里,写操作走自己的代码,顺手清缓存是基本操作——这还用说吗?
AI 不知道这还用不用说。Spec 描述的是读缓存的需求,它就只做了读缓存。写操作你没提,它就没碰。
你的常识,是 AI 的盲区
回头复盘那份 Spec,我发现一个规律:我漏掉的都不是我”忘了”的,是我”觉得不用写”的。
“支持搜索”——我没说用什么方案,因为在我经验里,数据量超过十万就该上索引,不会有人做全表 LIKE。AI 做了全表 LIKE,几千条数据飞快,数据量一涨就超时。
“记录操作日志”——我没说日志包含什么,因为在我经手的系统里,操作人、时间、变更前后值、请求 ID 是标配。AI 只记了操作人和时间,出了问题回溯不了现场。
“接口要做鉴权”——我没说过期 token 返回什么状态码,因为 401 是 HTTP 语义。AI 返回了 403,前端的 token 刷新逻辑被跳过,用户反复被踢到登录页。
每一条,AI 都”满足”了我的 Spec。每一条,我的理解和 AI 的理解都不是一回事。
格式没问题,五个字段都在。但我脑子里那些没写出来的潜台词,我觉得理所当然的部分,AI 根本看不见。
潜台词不是疏忽,是经验的副作用
你可能觉得这就是 Spec 没写够细。但回想一下第一篇 Spec 文章的结论:写太细本身就是问题,足够精确的 Spec 等于在用另一种语法写代码。
关键是你漏掉的那些东西,它们是什么性质。
它们是你做了几年工程之后形成的本能。全表 LIKE 在大数据量下不能用、缓存要做主动失效、401 和 403 的语义不同。这些东西你不会从文档里学到,它们是踩过坑之后长进肌肉里的反应。你在写”加缓存”的时候,脑子里自动带着”变更要清缓存”,就像你写”过马路”不会专门加一句”先看车”。
这些潜台词恰恰是你最值钱的工程判断。但它们有一个致命特点:越值钱的经验,越不会被写进 Spec——因为对你来说它太显然了。
AI 正好相反。你写了什么,它就看什么。Spec 里有”缓存失效时间 5 分钟”,它就做 5 分钟过期。你没说变更要清缓存,它就不清。它不是故意跟你对着干,是真的不知道你脑子里还有另一层意思。
你以为你说了 100%,其实你只说了 60%。剩下的 40%,AI 用它训练数据里最常见的方式填了。你不知道它填了什么,直到线上出了问题。
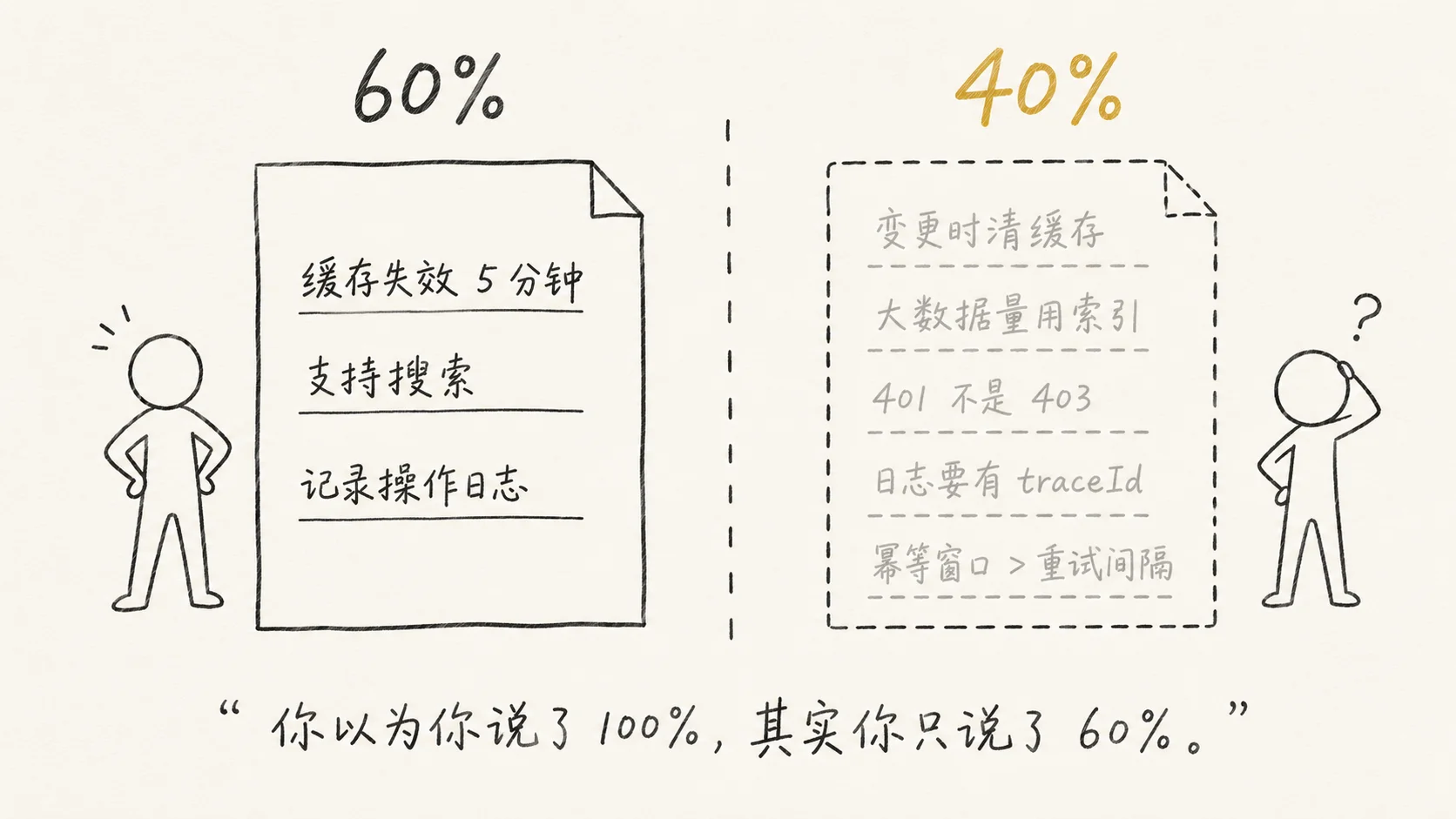
默认值之间的静默冲突
如果只是单个地方填错了默认值,review 的时候还有机会看出来。
真正危险的是,AI 在多个地方各自填了自己的默认值,这些默认值之间产生了你预测不到的冲突。
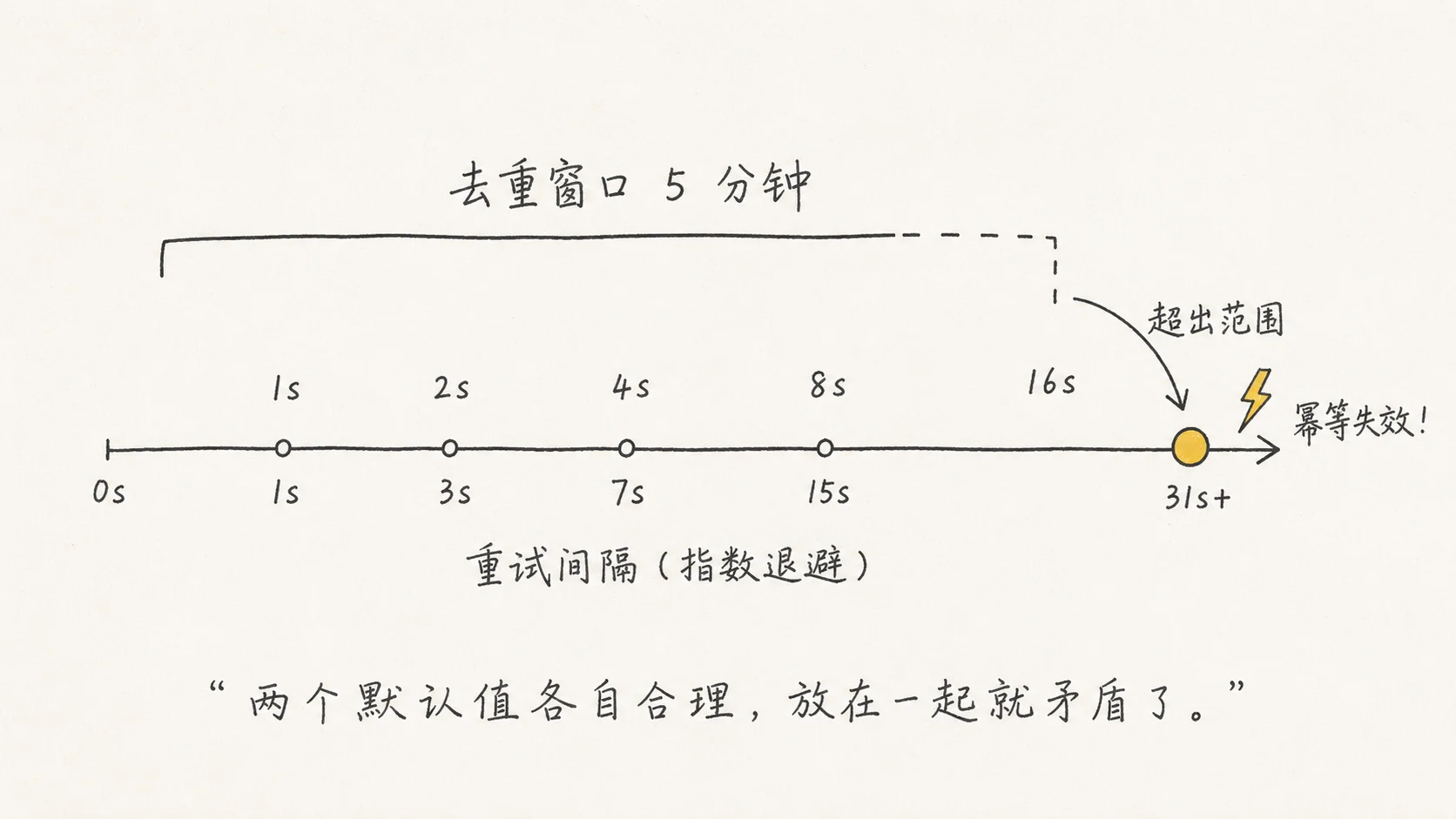
我遇到过一个例子。Spec 里写了两条需求:“消息消费支持重试”和”保证处理幂等”。AI 给重试加了指数退避,间隔 1 秒、2 秒、4 秒、8 秒、16 秒,合理。给幂等加了基于消息 ID 的去重窗口,5 分钟内同一 ID 视为重复,也合理。
但第五次重试的间隔是 16 秒,叠加队列本身的延迟,实际到达时间可能超过 5 分钟。去重窗口关了,这条消息被当作新消息再处理一次,幂等失效。
两个默认值各自合理,放在一起就矛盾了。我 Spec 里没写去重窗口要覆盖最大重试间隔——因为在我脑子里这是常识。
这种 bug 在 code review 里极难发现。你需要同时看到两个不同文件里的两个参数,在脑子里算出它们的数值关系。你越信任 AI 的输出,毕竟每个模块单独看都挺合理,越不会做这种交叉检查。
反过来写:先列出你觉得”不用说”的
我后来改了一步。
以前写 Spec 的流程是:想清楚要什么,按框架填字段,交给 AI。
现在多了一步:写完初稿之后,逼自己过一遍每条需求,问一个问题——“如果一个聪明但对我们项目一无所知的人看到这句话,他会怎么做?”
你的数据量级有多大、技术栈是什么、日志规范长什么样,他全不知道。你前端怎么处理 401 和 403,你上次因为缓存没清干净出过什么事故,这些对他来说不存在。
他只看到你写的字。
用这个视角过一遍,那些”不用写”的部分就会浮出来。把它们写进约束字段——“数据量可能达到百万级”、“数据变更后缓存必须立即失效”、“错误日志必须包含 traceId”——每条一句话就够。
这一句话,就是你的经验和 AI 的默认值之间的桥。
三篇 Spec 文章到这里,脉络是一条线:第一篇说别把 Spec 写成伪代码,第二篇说该写哪些字段,这篇说字段里别漏掉你觉得”不用写”的假设。
框架是骨架,但同一个框架,资深工程师和新手填出来的差在哪?差在资深工程师会把自己的潜台词翻译成显式约束,而新手不知道自己有潜台词。
Spec 的质量不取决于你写了多少,取决于你把多少”理所当然”变成了白纸黑字。
下次写完 Spec,假装你对这个项目一无所知,再读一遍。你会发现好多话你以为说了,其实只是想了。
版权声明
- 作者
- XingKaiXin
- 标题
- Spec 里最危险的,是你觉得不用写的部分
- 发布时间
- 2026年5月14日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。