不是不用 Spec,是你用错了——别告诉 AI 怎么做,告诉它什么不能做
不是不用 Spec,是你用错了——别告诉 AI 怎么做,告诉它什么不能做
上一篇我写了 SDD 的问题:spec 写得足够细,本质上就是在用另一种语法写代码,它没有消灭工程的复杂度,只是换了个地方藏起来。
有读者问:那你的意思是不要写文档?恰恰相反。我反对的不是文档,而是那种试图用自然语言把实现路径描述清楚的文档——它的成本太高,效果还不好。这篇想聊的是:你该写什么,以及怎么写,才能让文档真正变成驱动 AI 开发的燃料,而不是另一种形式的负担。
你该约束的是边界,不是路径
大多数人给 AI 的指令,要么太粗,要么太细。
太粗——“帮我写一个用户管理模块”。AI 自由发挥,写出来的东西可能跟你脑子里想的完全不是一回事。太细——用自然语言写伪代码,“先创建一个数组,然后遍历用户列表,对每个用户检查权限字段……”你写得比直接写代码还累,而且你描述的实现路径不一定是最优的,反而限制了 AI 的发挥。这是 spec 的两难困境:写少了 AI 跑偏,写多了你比 AI 还累。
但这个困境有解。关键不在于 spec 写多少,而在于你该告诉 AI 什么,不该告诉 AI 什么。传统的 spec 思路是:把实现细节描述得越清楚越好,AI 照着做就行。这个思路在简单任务上没问题。但一旦需求稍有复杂度,你会发现用自然语言去精确描述实现路径是一件极其痛苦的事——分支太多,交互太细,而且你花大力气描述出来的方案,很可能不如 AI 自己想出来的好,因为它见过的代码模式比你多得多。
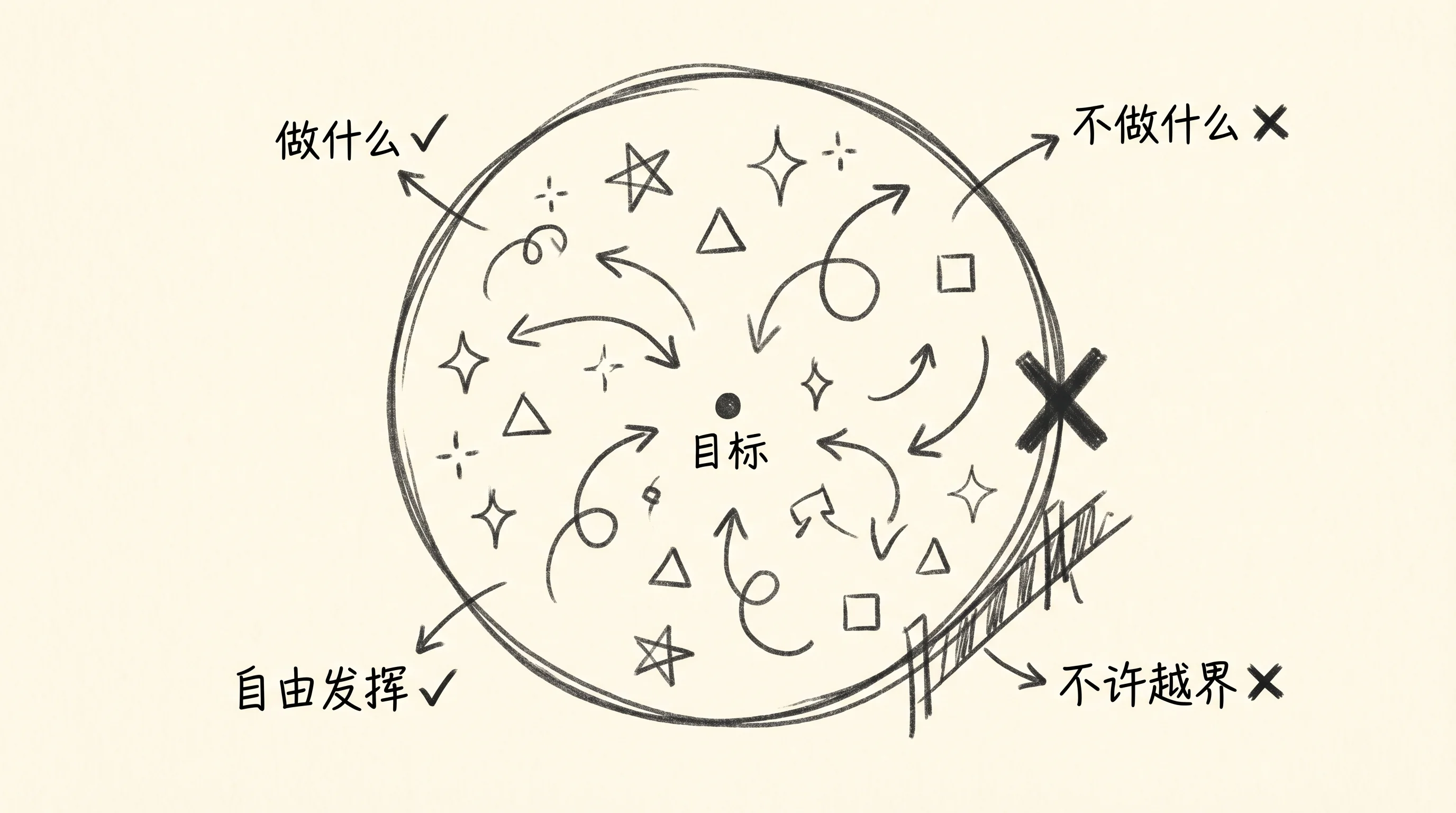
换个思路想:你写 spec 的目的不是给 AI 画一条路让它沿着走,而是给它画一个圈,圈内自由发挥,圈外不许越界。那这个圈怎么画?你只需要告诉 AI 三件事:
做什么。 明确的目标。不是”做一个好用的搜索功能”,而是”用户输入关键词后,在 500ms 内返回按相关度排序的结果,支持分页”。目标越具体,AI 的输出越可预期。这是圈心。
不做什么。 这一条被绝大多数人忽略,但它可能是防止 AI 跑偏最有效的手段。AI 的本能是”多做”——你让它做搜索,它顺手给你加了搜索历史、智能推荐、自动补全。每一个都合理,但你这个版本根本不需要。再比如你让它写一个数据导出接口,它可能自作主张加上定时任务、邮件通知、导出格式自动检测——这些功能未来可能要做,但现在加进来只会让代码变复杂、让测试变困难。明确地划出”不做”的边界,就是在画圈的外沿。
做成什么样算完。 验收标准。不管最终是 AI 自检还是人工验收,你需要一组可判断的条件来定义”完成”。没有验收标准的需求就像没有终点线的赛跑——AI 不知道什么时候该停,你也不知道什么时候该收。这是圈的出口。
这三条加在一起,本质上是在划定 AI 可以自主判断的范围。圈内的实现细节——用什么数据结构、怎么组织代码、调用哪个库——全部交给 AI 决定。你不替它做它擅长的事,你只负责那些 AI 判断不了的事:业务意图、系统约束、什么不能碰。
一份驱动 AI 开发的前置文档长什么样
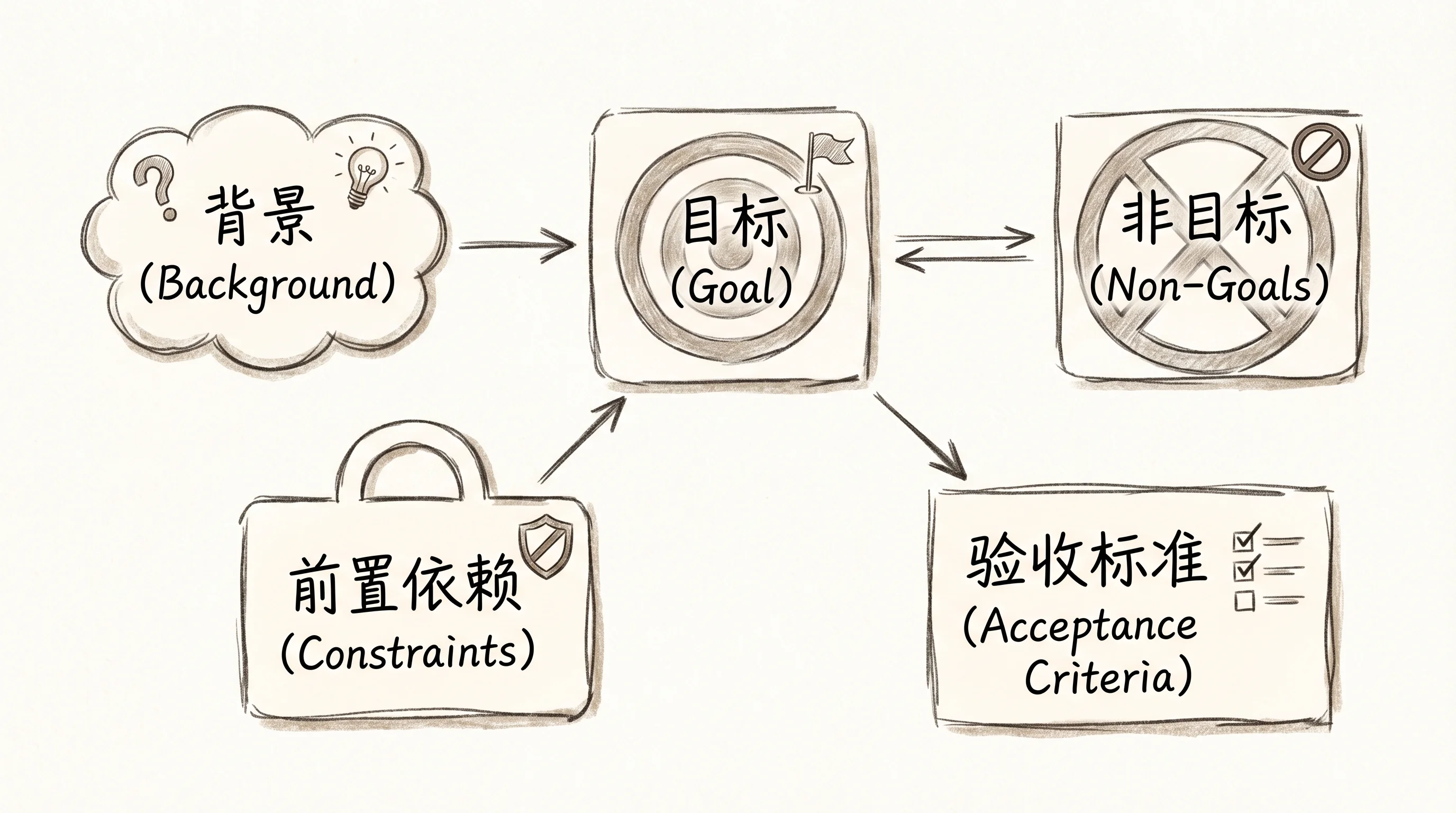
上面三要素——目标、非目标、验收标准——是这份文档的骨架。但要让 AI 真正理解你的意图并做出好的判断,还需要两个支撑项:背景告诉 AI 为什么要做这件事,让它在模糊地带有据可依;前置依赖和约束告诉 AI 哪些是不可逾越的硬边界。
我在自己的项目里摸索出了一套框架,核心就这五个字段:
背景。 为什么要做这件事。不是给人看的项目介绍,而是给 AI 提供决策上下文。AI 知道了”为什么”,才能在实现过程中遇到模糊地带时做出更合理的判断。比如”当前搜索用的是全表扫描,数据量增长后响应时间已经超过 2 秒,用户反馈明显”——AI 看到这个背景,就知道性能是核心关切,不会去做花里胡哨但更慢的方案。
目标。 这次要达成什么。具体、可衡量,最好能让 AI 自己判断做到了没有。
非目标。 这次明确不做什么。你列出的每一条非目标,都在帮 AI 收窄决策空间,减少它生成不必要代码的概率。这是整份文档里投入产出比最高的部分——花两分钟想清楚不做什么,能省掉后面大量的返工。
前置依赖和约束。 必须兼容的现有接口、不能动的模块、技术栈限制、性能要求。这些是硬性边界,AI 在边界内自由发挥,但不能突破。
验收标准。 怎样算做完了。可以是具体的测试用例,可以是行为描述,关键是要可判断——不是”搜索功能好用”,而是”输入关键词后 500ms 内返回结果,空关键词显示默认列表,结果按相关度降序排列”。
就这几项。注意这里面完全没有出现”怎么实现”。你没有告诉 AI 用什么算法、怎么组织文件结构、调用链怎么走。你只画了一个圈:目标在圈心,非目标和约束是边界,验收标准是终点线。圈内的一切,AI 自己决定。
这份文档不需要很长。一个中等复杂度的需求,可能也就半页到一页。但它的信息密度极高,因为每一句话都在传递 AI 真正需要的东西:上下文、边界和预期。
这份文档本身也是人机协作写出来的
那不还是要我花时间写文档吗?
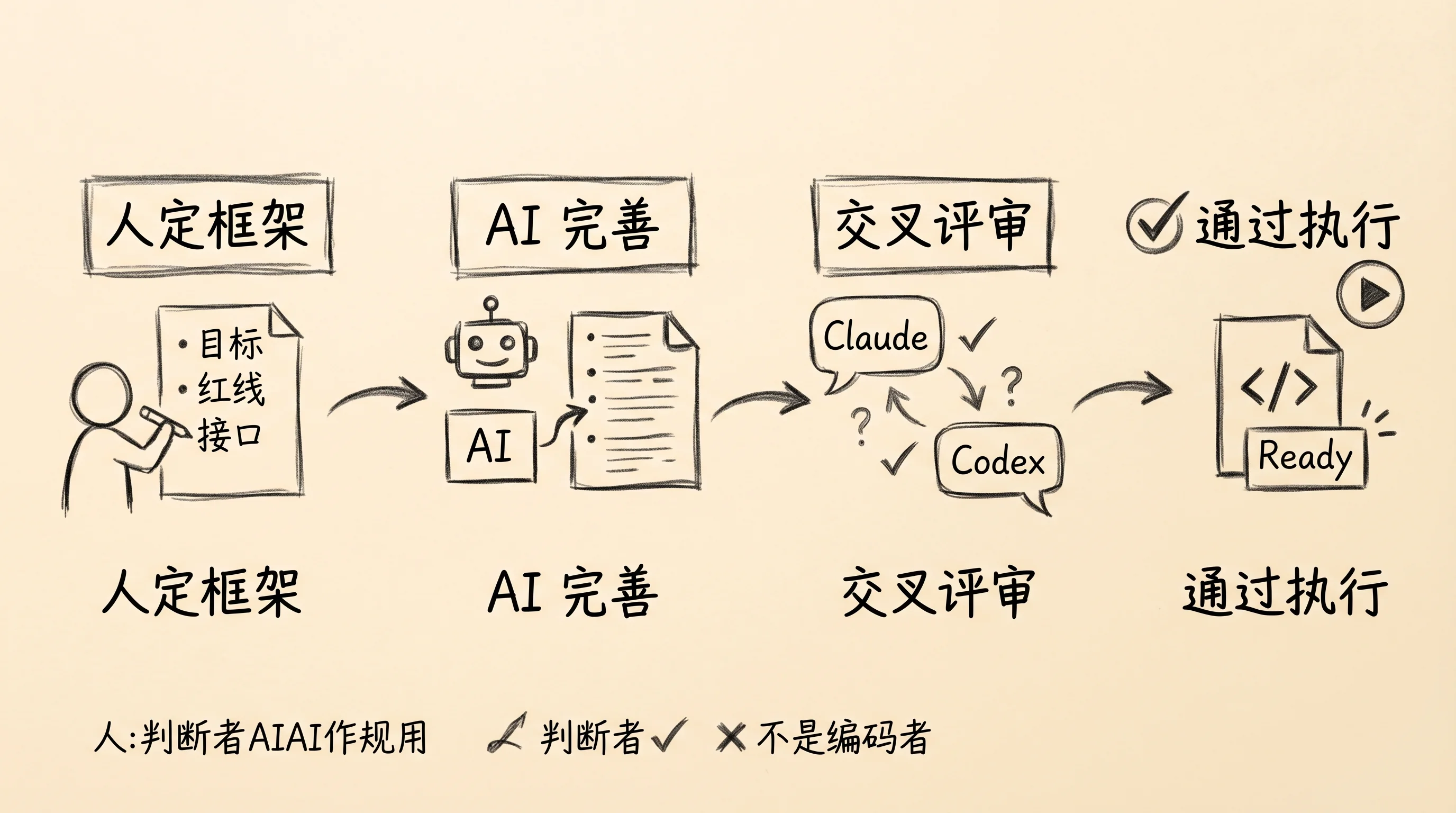
是,但花的时间远比你想的少——因为这份文档本身也是人机协作的产物,而且分工非常清晰。你来填那些只有你知道的东西:核心目标是什么,绝对不能碰的红线有哪些,必须兼容的现有接口是什么。这些是 AI 猜不到的业务判断,需要你来定。可能就是几条要点,十分钟以内。
然后把半成品交给 AI 来补充完善。AI 擅长的是根据你给的背景和目标,展开你可能遗漏的边界条件;把你模糊的意图翻译成更精确的验收标准;发现你列的约束之间有没有潜在的冲突。这些是它的强项——比你更擅长穷举和检查一致性。
最后一步,也是容易被跳过的一步:评审。如果你在用多模型的工作流,这里有一个我自己在用的做法:让补充文档的模型和评审文档的模型不是同一个。
不是因为谁更强。不同模型的训练方式和内部偏好不一样,一个模型的盲区,往往恰好是另一个模型的敏感地带。用同一个模型写完再自检,它大概率看不到自己的问题——就像让一个人写完代码再自己审,审出来的 bug 会比另一个人来审少得多。
我通常的做法是:Claude Code 负责根据我的框架展开文档,然后把这份文档喂给 Codex 做评审。评审的关注点只有三个:目标和非目标有没有矛盾,约束条件有没有遗漏明显的边界,验收标准能不能真正判断”完成”。
举个真实的例子:我之前做一个数据导出功能,Claude Code 帮我展开的文档里写了”支持 CSV 和 JSON 两种格式”,约束条件里写了”单次导出数据量不超过 10 万行”。Codex 评审时指出:你的验收标准里只写了”导出成功”,但没有覆盖边界情况——10 万行的 CSV 文件大概有多大?如果超过内存限制怎么办?需不需要流式写入?这个问题如果等到代码跑起来才发现,可能要推翻整个实现方案。加一条验收标准——“10 万行 CSV 导出内存占用不超过 256MB”——就把这个坑提前填上了。
这一轮评审不是在挑毛病,是在帮你在执行之前找出文档里的漏洞——这些漏洞如果等到代码写到一半再发现,修复成本会高很多倍。
评审通过之后,这份文档才正式成为开发的输入。模型基于它去写代码,目标清晰、边界明确、验收可判断,跑偏的概率大幅下降。即使需要调整,你也知道该从哪个字段入手——是目标不够准?是约束漏了一条?是验收标准没覆盖某个场景?
不是所有任务都需要这份文档
需要说清楚:这套流程不是万能的,也不应该什么场景都用。修一个简单的 bug,直接告诉 AI 哪里出问题就够了,不需要写文档。十分钟能搞定的小功能,也不需要。
但当你面对一个需求——它涉及多个模块的联动,有必须兼容的外部接口,你脑子里有明确的预期但不是一两句话能说清的——这时候花十几分钟写一份前置文档,往往能省掉后面几个小时的返工。
判断标准很简单:如果你发现自己在跟 AI 反复拉扯——“不是这样的”、“我说的不是这个意思”、“这个功能不需要”——那就说明你该在动手之前先写这份文档。 你跟 AI 拉扯的每一轮对话,本质上都是在补前置文档里缺失的信息。与其事后一轮一轮地纠偏,不如事前一次性把边界画清楚。
把注意力投在最有杠杆的地方
回头看整个流程:人定框架和硬约束,AI 补充完善,多模型交叉评审,评审通过后交给模型执行,人做最终验收。你在整个链条里的角色从头到尾都是判断者——判断目标对不对,判断边界合不合理,判断结果符不符合预期。中间的展开、检查、执行,全部可以交给 AI。
这才是 Agentic 时代工程师应该投入注意力的方式:不是盯着 AI 写的每一行代码,而是把精力集中在最有杠杆的环节——前置的约束定义,和最终的验收判断。这两个环节做好了,中间那条长长的执行链,AI 自己能跑得很稳。你不需要成为一个更快的编码者,你需要成为一个更好的判断者。而一份好的前置文档,就是你把判断力变成 AI 可执行指令的那个翻译器。
上一篇我写了 SDD 的幻觉:足够精确的 spec,本质上就是代码。这篇是另一面:你不需要写那么精确,但你需要写对地方。如果你在用 AI 开发,有自己的一套前置文档习惯,欢迎在评论区聊聊。
版权声明
- 作者
- XingKaiXin
- 标题
- 不是不用 Spec,是你用错了——别告诉 AI 怎么做,告诉它什么不能做
- 发布时间
- 2026年4月11日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。