skill 越写越长,agent 反而越用越偏
skill 越写越长,agent 反而越用越偏
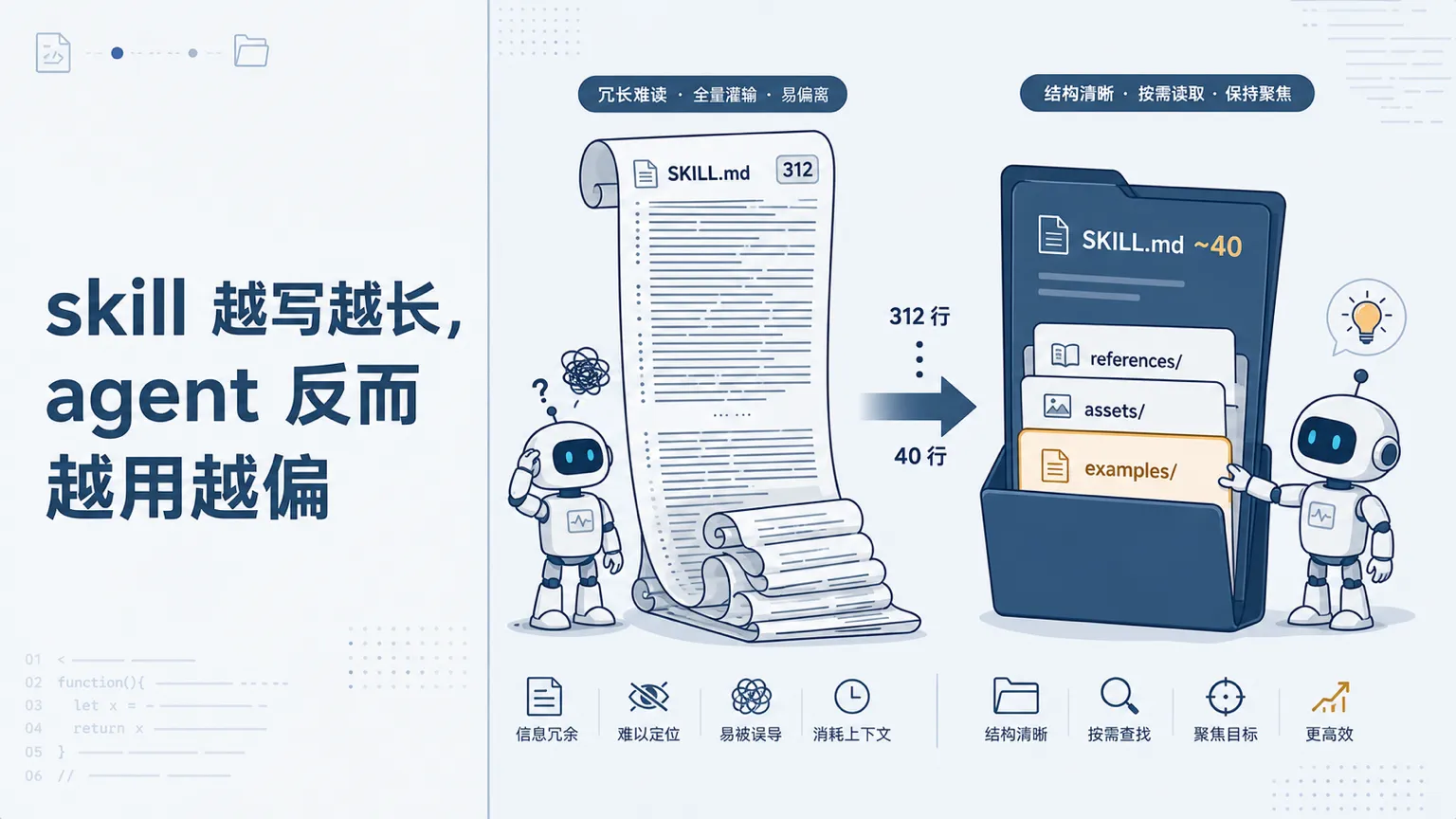
周日晚上,我打开那个管选题的 SKILL.md,准备再给它补几条规则。光标拉到底:312 行。三周前 Claude 刚生成它的时候,我记得很清楚,87 行。
中间多出来的两百多行,每一行都有来历。它该触发的时候不触发,我加了一节”使用场景”;它把选题判断和排版规则搅成一坨,我加了一节”注意事项”;它输出格式飘忽,我又往里贴了四个完整的正反例。每次出问题,我都回来喂它几句。每次喂完,文件长一截,下次用,偏得更厉害。
那天晚上我没有再加。因为我刚读完 Claude Code 团队那篇 skill 复盘,里面的判断正好戳在这个文件上:问题不在规则写得够不够细,在于写得太多。而当 skill 是 agent 替你生成的,“太多”几乎是默认结果。它最擅长的就是把话说全,而一个好 skill 要的恰恰是反过来。
skill 是文件夹,不是说明书
把 skill 理解成”一段写给 AI 的说明书”,人就会本能地往里堆字:所有规则、所有边界、所有例外,全写进一个 SKILL.md。agent 替你生成时更是如此,“写全”是它阻力最小的路。文件越长,你越觉得这下它该懂了。
但 skill 真正的单位是文件夹。里面可以放脚本、模板、参考资料、示例数据,agent 能发现、能读、能调用。SKILL.md 只是入口,它的活儿是告诉 agent 这里有哪些文件、什么时候去翻哪一个,而不是把所有内容一次性摊在它面前。
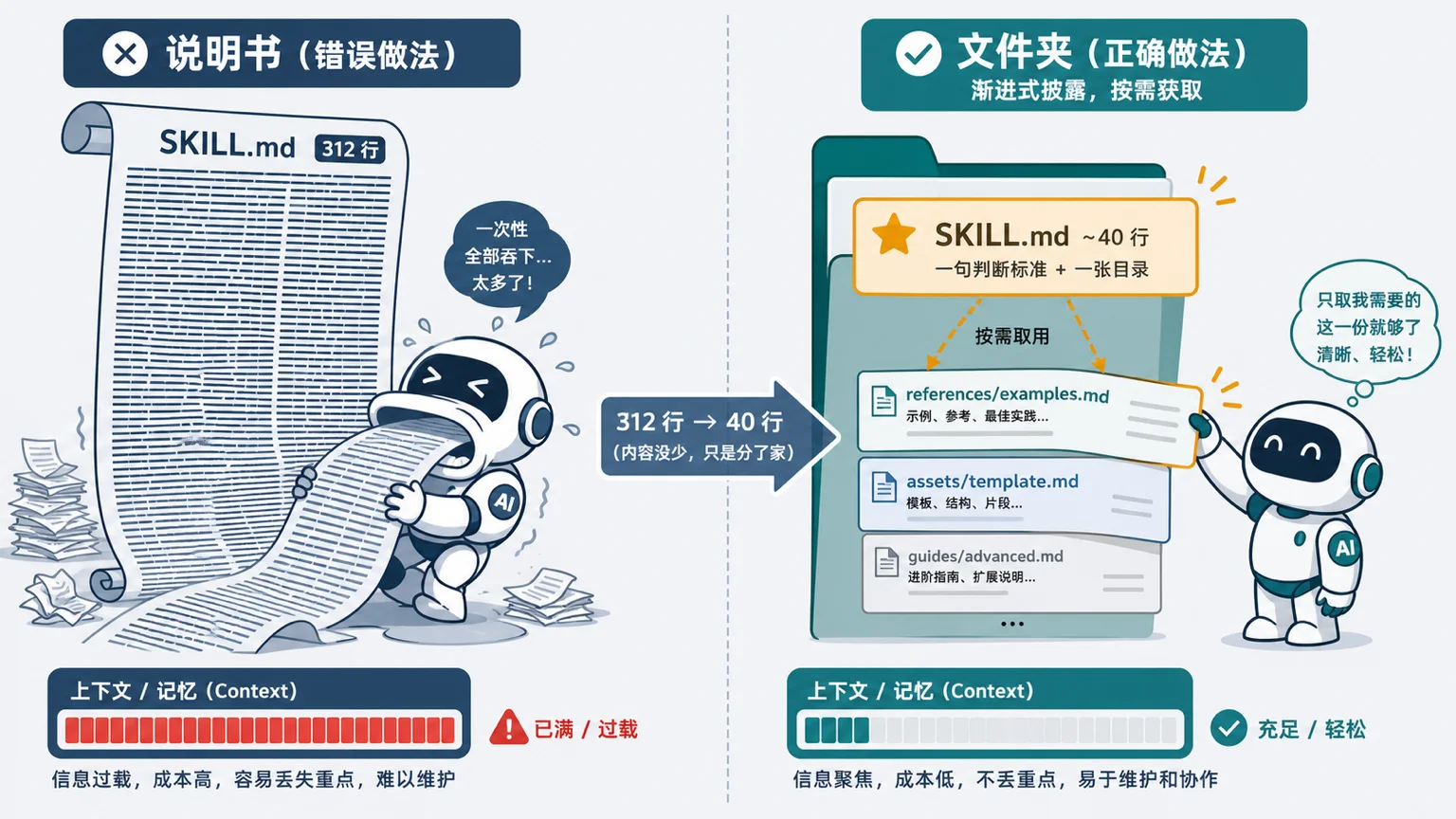
这背后是一个叫 progressive disclosure 的思路:上下文是稀缺资源,不该一次性灌满。SKILL.md 留一张目录,详细的函数签名放 references/api.md,输出模板放 assets/,agent 用到哪个才去读哪个。一个三百行的 markdown,等于强迫 agent 每次都把全部规则吞进上下文。我那个选题 skill 每次触发,都要先把排版规则连同四个正反例一起读进去,等真正开始判断选题,注意力已经被稀释掉一半。
我后来做的就是拆。SKILL.md 删回四十多行:一句话的判断标准,加一张文件目录。正反例挪进 references/examples.md,输出格式挪进 assets/template.md。内容一个字没少,只是分了家。第二天再用,它头一回把选题判断和排版分开了。不是写得更清楚了,是不再逼它一口吞下全部。
最该写的,是 AI 默认不会做的那部分
Claude Code 团队还有一句更扎心的话:Claude 本来就会写代码、也能读你的代码库,一个只是复述它默认行为的 skill,只增加上下文,不增加价值。
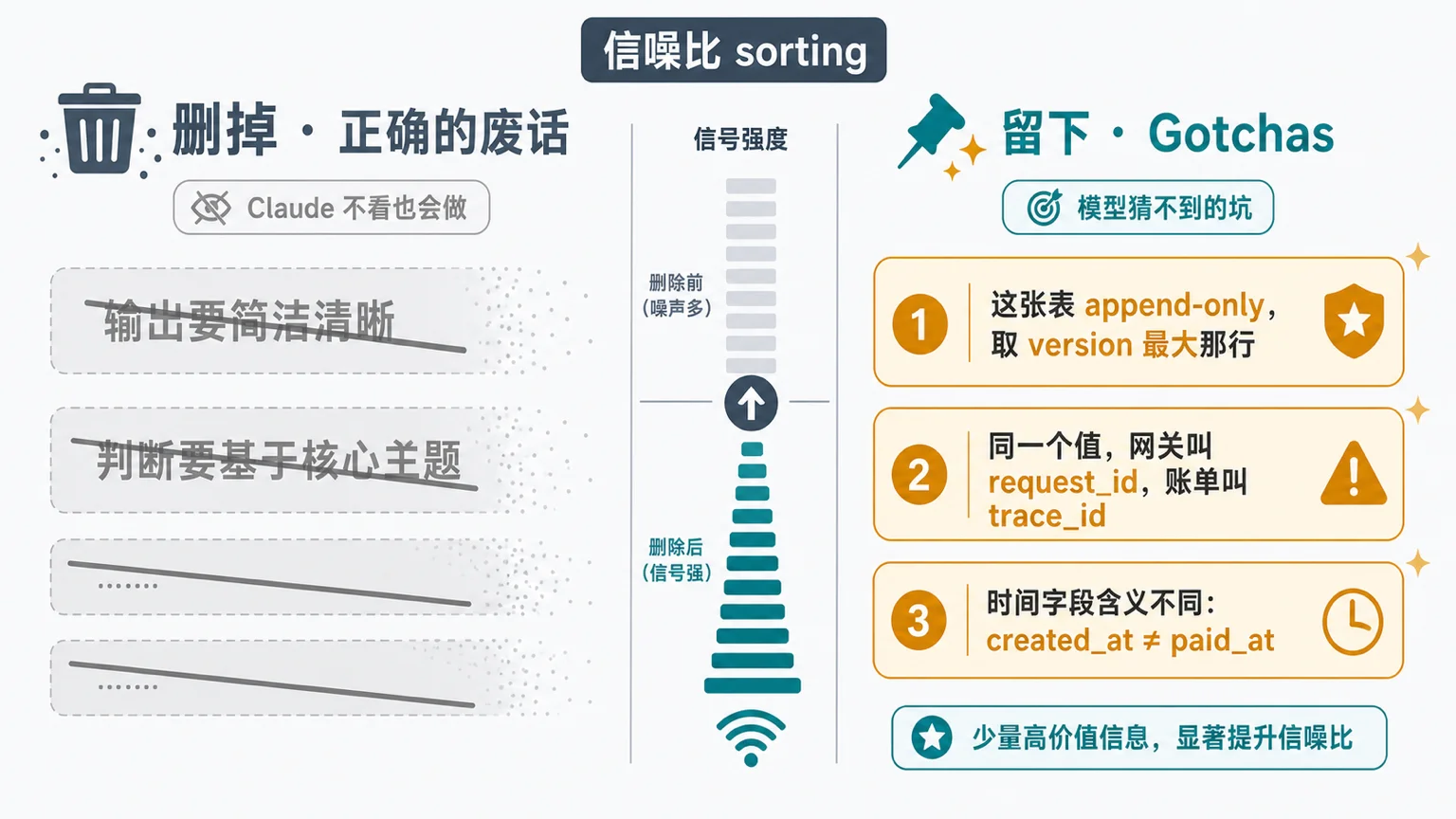
拿这句话回头翻那 312 行,至少一半是”正确的废话”。“输出要简洁清晰""判断要基于文章核心主题”,这些话删掉,Claude 照样会这么做。它们不光没用,还占着位置,稀释真正的信号。agent 生成 skill 时,复述常识是它最顺手的填充,所以人在这一步的活儿主要不是写,是删。
一个 skill 里信噪比最高的部分,是 Claude Code 团队叫 Gotchas 的那一节:那些只有你亲手踩过、模型绝对猜不到的坑。比如”这张表是 append-only 的,你要的是 version 最大的那行,不是 created_at 最新的那行""这个字段在网关里叫 request_id,在账单服务里叫 trace_id,是同一个值”。我的选题 skill 里真正值钱的也就那几行:哪类题和已发布文章撞了车、哪个来源的素材只能当线索不能直接进候选。模型推不出来的东西,写进去才算数。
判断一句话该不该留,标准就一条:如果 Claude 不看这句也会这么做,这句就是噪声。
description 是写给模型的触发器
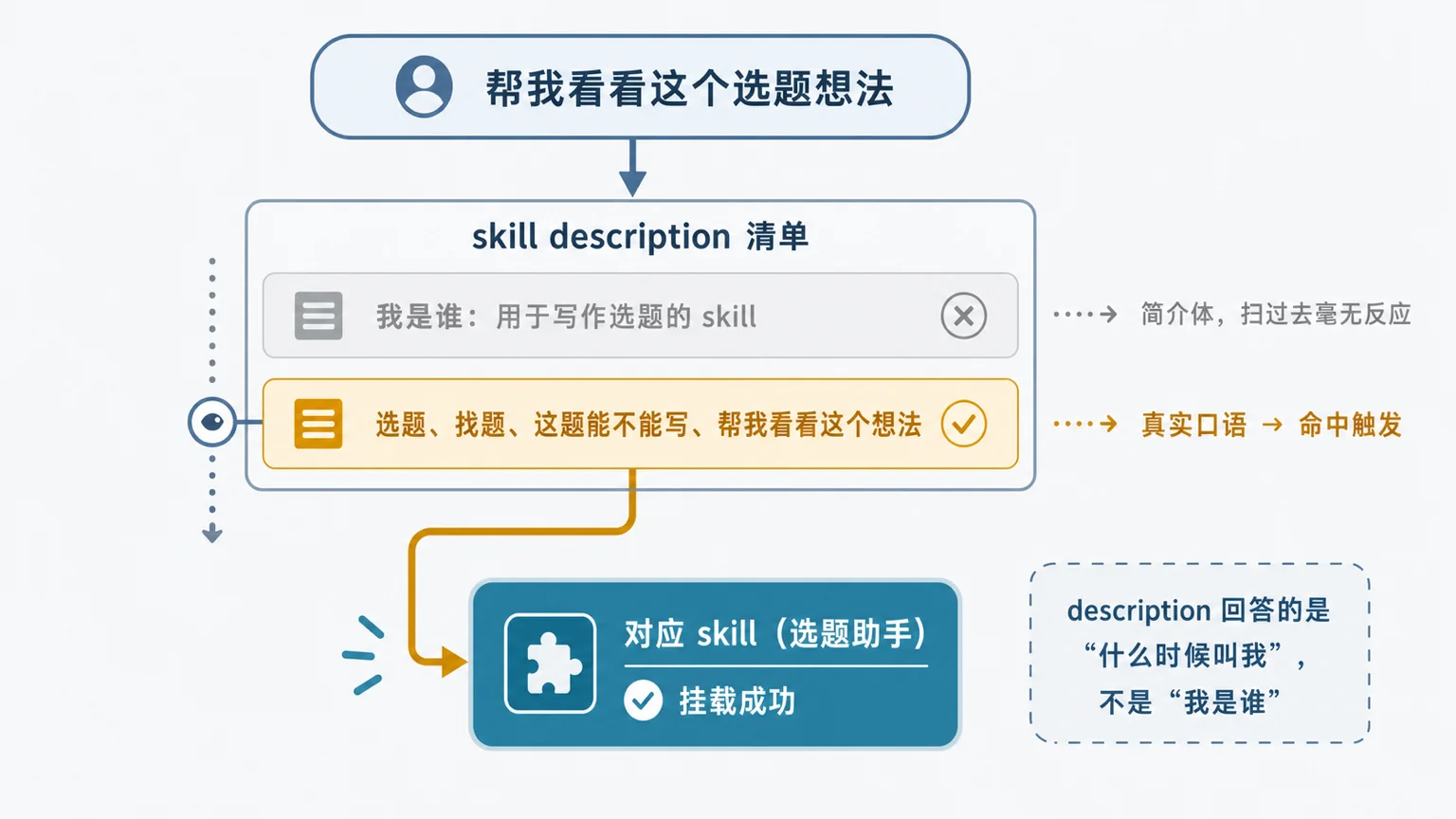
它该触发时不触发,病根不在正文,在 description。
Claude Code 启动时,会把每个 skill 的 description 列成一张清单,靠扫这张清单决定当前请求要不要挂哪个 skill。所以 description 的本职是回答”什么时候该叫我”,而我原来那句”用于写作选题的 skill”,回答的是”我是谁”。标准的简介体,模型扫过去毫无反应。
后来改成把我真实会说出口的话写进去:“选题、找题、这题能不能写、帮我看看这个想法”。当天触发率就正常了。
顺带一个反直觉的点:description 写准了,正文反而要松。skill 是要跨场景复用的,正文写得越像一条铁轨,agent 在新场景里就越僵。给足信息,留出让它随机应变的余地。
一个 skill 只许干一类事
Claude Code 团队把内部几百个 skill 归成了九大类,从库参考、产品验证到 CI/CD、排障 runbook。九类不用背,值钱的是他们从中拎出的判断:最好的 skill 干净地属于一类,想做太多事的 skill 会横跨好几类,把 agent 搞糊涂。
这就绕回了那 312 行的病根。我的选题 skill 既想管选题判断,又想管排版输出,横跨两类,agent 拿到它,自然不知道该用哪一半。写得长是症状,贪多才是病:一个 skill 想覆盖的事越多,它必然越长,也必然越容易被用偏。
现在那个 SKILL.md 停在四十多行,再没涨回去过。倒不是我克制,是每次想往里加东西,都先过三个问题:这件事只属于一类吗?这句话 Claude 不看也会做吗?description 里有没有我真实会说的那句话?
下次 agent 给你生成一个 skill,别扫一眼就收下。它写得多,你删得狠,agent 才会真的用对它。
版权声明
- 作者
- XingKaiXin
- 标题
- skill 越写越长,agent 反而越用越偏
- 发布时间
- 2026年6月25日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。