
8 天 + 16 天 + 1 天:我不打算把 AI 编程跑成马拉松
8 天 + 16 天 + 1 天:我不打算把 AI 编程跑成马拉松
3 月 12 日凌晨,我提交了项目主体的最后一个 commit。代码不算多,大约 4000 行,从 3 月 5 日开工算起,跨度 8 天。
按一般 AI 编程文章的写法,我接下来应该立刻进入”持续优化”状态 —— 重构、补测试、加文档、再迭代几个新功能。这是我用了大半年 AI 编程之后,看到的几乎所有人推荐的姿势:项目一旦跑起来,就别让它停。
但接下来 16 天,我什么都没改。
更诚实地说,前一周左右是我没空管它,被别的工作打断了。但等到第二周中段,我心里其实已经有空了 —— 那一刻我做了一个决定:继续不要碰它。
为什么?这就是这篇文章想讲的事。
8 天:写得很猛,但所有动作都是有计划的

先把”快”这件事说清楚,免得读者以为我在反对效率。
3 月 5 号的第一句话,我没有跟 Codex 说”帮我写个 CLI”。我贴了一段 30 多行的设计稿过去,包含了完整的命令结构、配置文件 schema、目录约定,甚至明确写出了我对开发包的偏好(pyright、pytest、ruff、ty)。
一个使用 python 实现的数据查询命令行工具,需要做登录鉴权和 token 的管理。
命令行的基本流程,首先需要用户登录,没有登录情况下,其他命令都提示用户登录。
...
# 登录与账号
ds status, ds login, ds whoami, ds logout
# 数据源
## ds obj {objId/ObjName}
- 条件查询 --where {field} {op} {value}
...这是我跟 AI 协作的第一个原则:我先想清楚我要什么,再开口。如果我没想清楚,我至少要让 AI 知道我不知道什么。
接下来 8 天,我跟 Codex 进行了 39 个会话,121 条用户消息。从工具调用次数看,平均每天会触发 280+ 次 exec_command,80+ 次 patch。强度不小。
但关键是:这 39 个会话之间,大部分是连贯的。今天写完登录,明天写数据查询;今天发现一个边界 case,明天专门去补它。每一步都建立在前一步的基础上。
到 3 月 12 日凌晨,主体功能完成 —— 登录、三种数据查询(对象/专题/指标)、缓存、日志、配置体系、测试覆盖率 92%、PyPI 发布脚本。
我以为接下来一个月会是”持续打磨”。实际不是。
16 天:被打断,然后我决定继续不动它
3 月 13 日开始,我被工作上别的事情拽住了。这种事很常见,做技术的人都懂 —— 你以为接下来一周可以专注做某件事,结果周一晚上就有个 P0 issue 砸过来。
那一周我停止了迭代这个工具。
但我在用它。
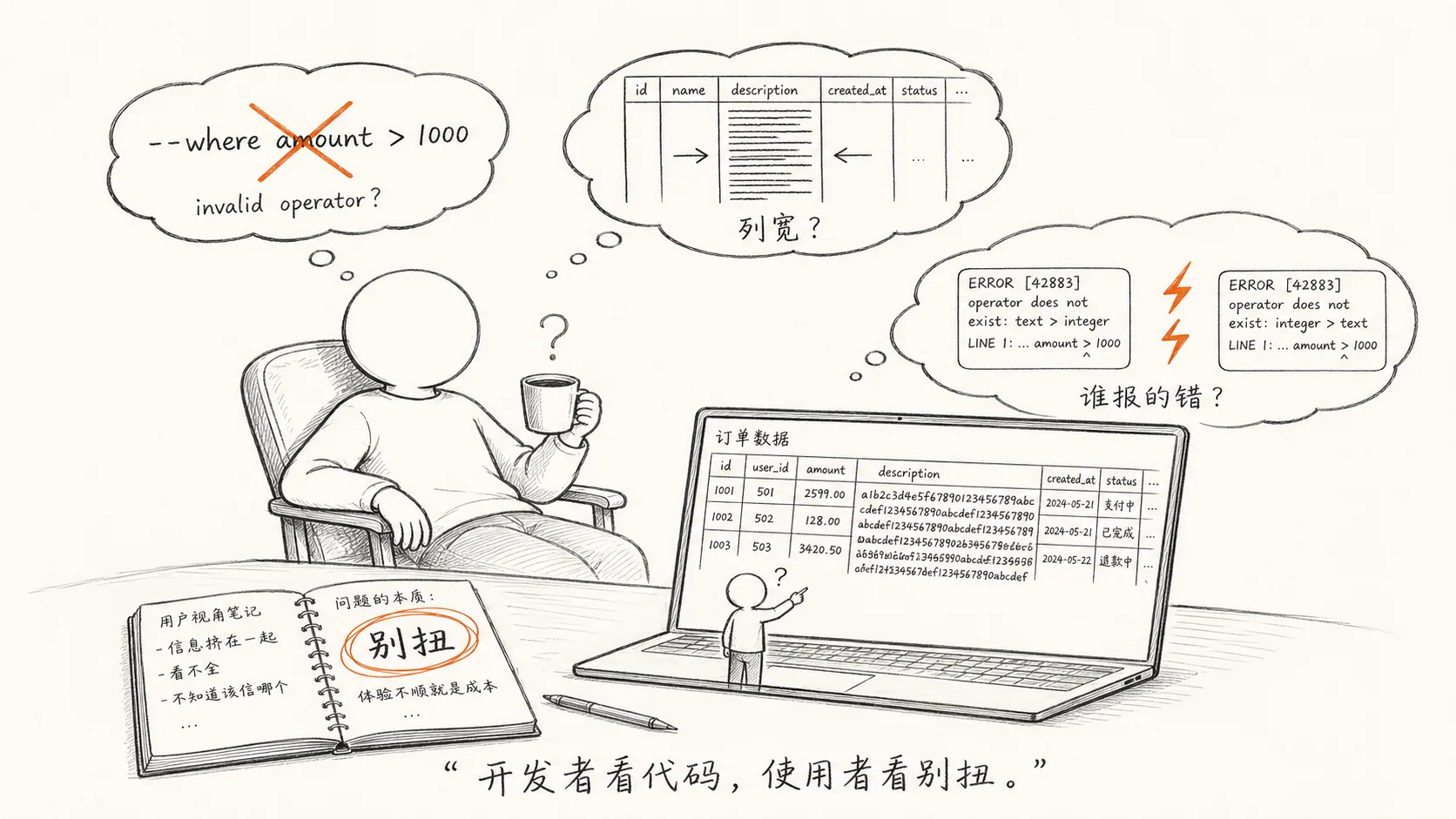
这是这篇文章里真正想跟你聊的事:当你只是”使用者”而不是”开发者”的时候,你看代码的眼睛是不一样的。
举几个具体的例子。我那 16 天里在用这个工具查公司内部的金融数据,踩到的几个问题:
第一个别扭是 --where 的语法。我在设计的时候定的是 --where {field} {op} {value},比如 --where amount gt 1000。但我自己用的时候,十次有六次会先写成 --where amount > 1000,然后被报错。错误提示是 invalid operator,我愣了一下才想起来要去查文档。问题是,我自己写的工具,我自己都记不住这个约定。
第二个别扭是表格输出。review 测试数据的时候,所有列都对得很齐,看起来很舒服。但当我查一个真实的基金持仓表,其中一个 portfolio_id 是 32 位的哈希字符串,结果那一列把后面的 nav 和 yield 挤到屏幕外面去了。我本能地去缩终端窗口,后来才意识到是工具的列宽算法没有考虑极端值。
第三个别扭是错误提示的层级。有一天晚上我在调一个查询超时的问题,工具返回了一个 RequestError: upstream timeout,但我看了五分钟日志才发现,这个错误其实来自缓存层,不是来自数据源。日志里两个模块都打印了几乎一样的错误信息,我在错误堆栈里来回翻了三四遍才定位到真正的问题。那一刻我非常清楚,这个错误提示在我写的时候觉得”够用了”,但在真实场景里就是废纸。
这些问题,都是我作为开发者在 review 阶段永远发现不了的。因为开发者看代码,看的是”我有没有写对”;使用者用工具,看的是”我用着有没有别扭”。
到 3 月 20 日左右,我手头的别的事情终于告一段落。我打开这个项目的目录,本来打算继续写那些一直想加的优化功能。
但坐在屏幕前,我突然停下来了。
我意识到一件事:我作为使用者积累的这些”别扭”,是这个项目接下来最有价值的输入。如果我现在立刻进入”开发者模式”开始写新代码,我会用开发者的视角覆盖掉使用者的视角。这些别扭被我自己消化掉,变成”我写的时候觉得理所当然的事”,然后我就再也看不见它们了。
所以我做了一个反直觉的决定:继续不动它。让自己再多用几天,把那些”别扭”沉淀成具体的问题清单,而不是模糊的不爽感。
接下来一周,我每次用这个工具的时候,如果遇到不顺手的地方,就在脑子里打一个标记。有时候打标记之后我会写到笔记本里。但更多时候,我让它自己留在那里 —— 因为我相信,真正重要的问题,会反复出现。出现得多了,我自然会记住;只出现一次的,可能本来就不重要。
1 天:回到现场,但带着新的眼睛

3 月 28 日上午 7:49,我打开了那个项目目录。
距离我上一次写代码,过去了 15 天 14 小时。
那一天我做的事情,你可能在我上一篇文章里看过 —— 用同一句 prompt,让 Codex 进行了 10 轮代码 review,从早上 7:49 到中午 10:18,大约 2.5 小时。
但那篇文章我没说的是:我能在那 2.5 小时里高效推进,完全是因为前面的 16 天。
具体说,16 天的”使用者视角”给了我两件东西:
第一,我有了一份非常具体的”哪里别扭”清单。当 Codex 在第 3 轮指出日志层职责混杂的时候,我立刻就知道要不要修 —— 因为我自己用的时候,日志里那个混乱的输出格式让我看错过两次错误来源。它说的不是抽象问题,是我作为使用者已经付出过代价的具体痛点。
第二,也是更重要的,我有了”什么时候停”的判断。AI 永远能在你的代码里再找到下一个问题 —— 我后面会在另一篇文章里讲这件事。但如果你心里没有”作为用户什么是够用的”这把尺子,你会被 AI 拖着无限重构下去。我那天能在第 10 轮干净利落地停下来,是因为我心里清楚:剩下的问题,没有一个是我作为使用者真的会被绊到的。
如果我不停下来那 16 天,我那 2.5 小时大概会变成 5 小时,而且产出可能更糟 —— 因为我会按”代码视角”修一堆我从来不会被它困扰的问题。
我现在怎么看 AI 编程的”节奏”
AI 编程最容易让人陷入的陷阱,不是 AI 写不好代码,而是 AI 让你随时都能写代码。
人类工程师以前的”节奏”是被外部条件强加的:你需要查文档、等同事 review、跑长时间的测试、等 CI、等部署。这些”等”看起来是低效,但它们里面藏着一个隐形的生产力机制 —— 让你脱离开发者视角的时间。
AI 把这些”等”全部消除掉了。文档随时可以问,review 随时可以做,测试秒级跑完。你可以从早上 9 点写到晚上 9 点,中间不需要离开开发者视角一秒钟。
这是一种新的危险。它让你永远离自己的代码太近。
我这次的解决办法,是用”人为的停顿”替代以前的”被动的等”。具体怎么做,坦白说我自己也是边走边摸:
1. 项目主体完成后,强制让自己进入”使用者”角色。 不再用 IDE 打开它,只用命令行调用它。如果你做的是别的类型的项目,等价物可能是:不再看代码,只用产品。
2. 不要立刻把”使用中遇到的别扭”翻译成”代码任务”。 让它停留在”我用着不爽”这个层面一段时间。多用几次,让真正重要的问题反复出现。
3. 等你重新打开 IDE 的那一刻,先用一句话写下”我作为使用者最难受的三件事”。 这一句话,会成为你接下来所有重构的”用户视角”标尺。没有它,AI 会给你建议无穷无尽的”代码视角”问题,你会被淹没。
这个方法适不适合所有人?我不知道。但这个项目它适合。8 + 16 + 1 这个节奏,跟我以前任何一个项目都不一样,而且它的产出比我预期的好。
最后
那 16 天里,我有过几次差点忍不住打开 IDE 的瞬间。AI 编程的诱惑很真实 —— 它让你觉得”反正动一下就能改”,于是每一个小别扭都想立刻动手。
但我后来发现,克制住那个”立刻动手”的冲动,比真的动手更难,也更值钱。
8 天写代码,16 天用代码,1 天审代码。这不是 AI 让我能写的最快的姿势,但可能是 AI 让我能写得最对的姿势。
下一个项目我还会用这个节奏吗?不一定。每个项目有自己的体量和压力。但 AI 编程让我多出了一个以前没有的选项:我现在可以自己决定我什么时候在场,什么时候不在场。
这件事比”AI 让我写代码更快”重要得多。
这是这个项目的第二篇。第一篇讲的是 3 月 28 日那天 10 轮 review 的细节。
版权声明
- 作者
- XingKaiXin
- 标题
- 8 天 + 16 天 + 1 天:我不打算把 AI 编程跑成马拉松
- 发布时间
- 2026年4月30日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。