KV Cache:为什么 AI 回复越来越快?
KV Cache:为什么 AI 回复越来越快?
你有没有注意到,当你跟 AI 聊天时,它的第一个字往往需要等一会儿,但一旦开始输出,后面的内容就会源源不断地涌出来?这背后的关键技术叫做 KV Cache。
AI 是怎么”说话”的?
要理解 KV Cache,先得知道大模型是怎么生成文字的。
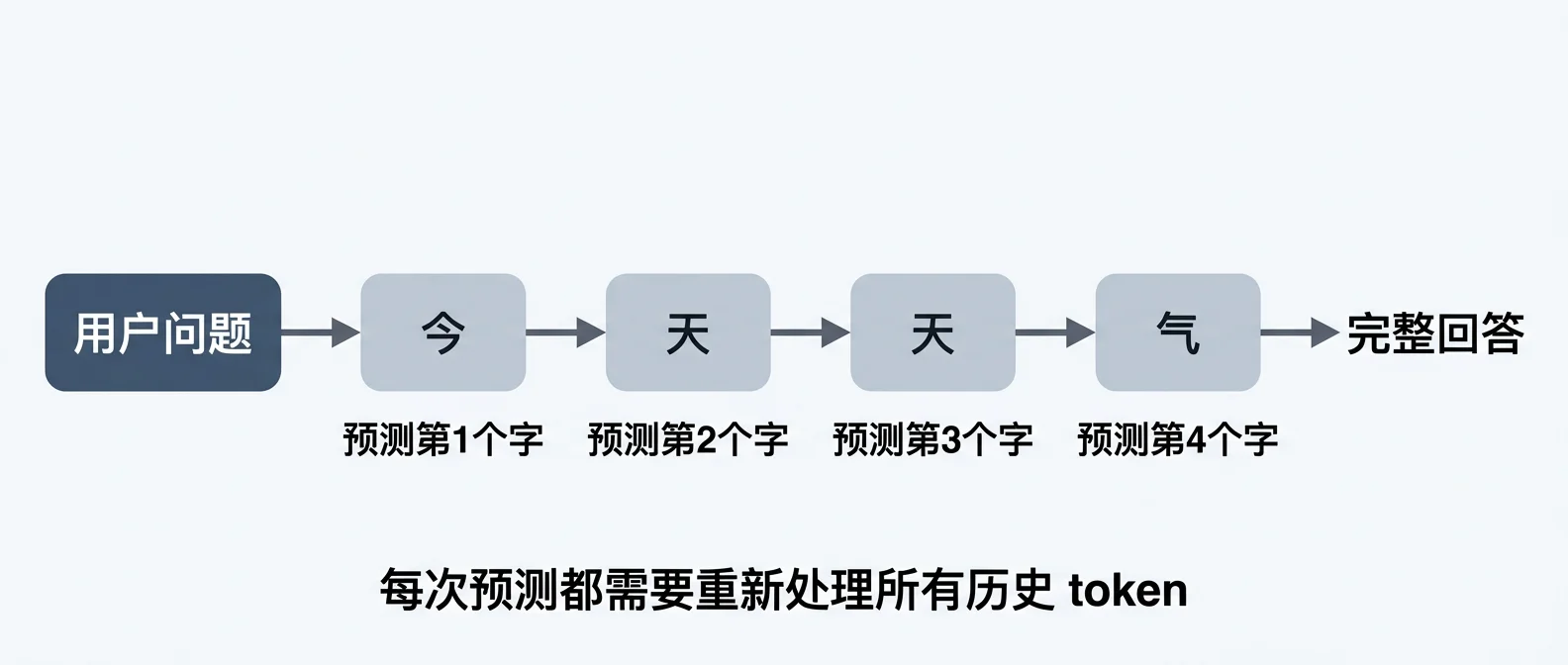
AI 不会一口气想好整段回答。它每次只预测下一个字,加到末尾,再预测下下一个,如此循环。
举个例子:AI 要输出”今天天气真不错”时,实际经历了:
- 看到问题 → 预测”今”
- 看到”今” → 预测”天”
- 看到”今天” → 预测”天”
- 看到”今天天” → 预测”气” ……依次推进。
但这里有个关键问题:每预测一个新字,模型都要把前面所有的内容重新处理一遍。对话如果有几百字,这几百字就要被反复计算无数次。
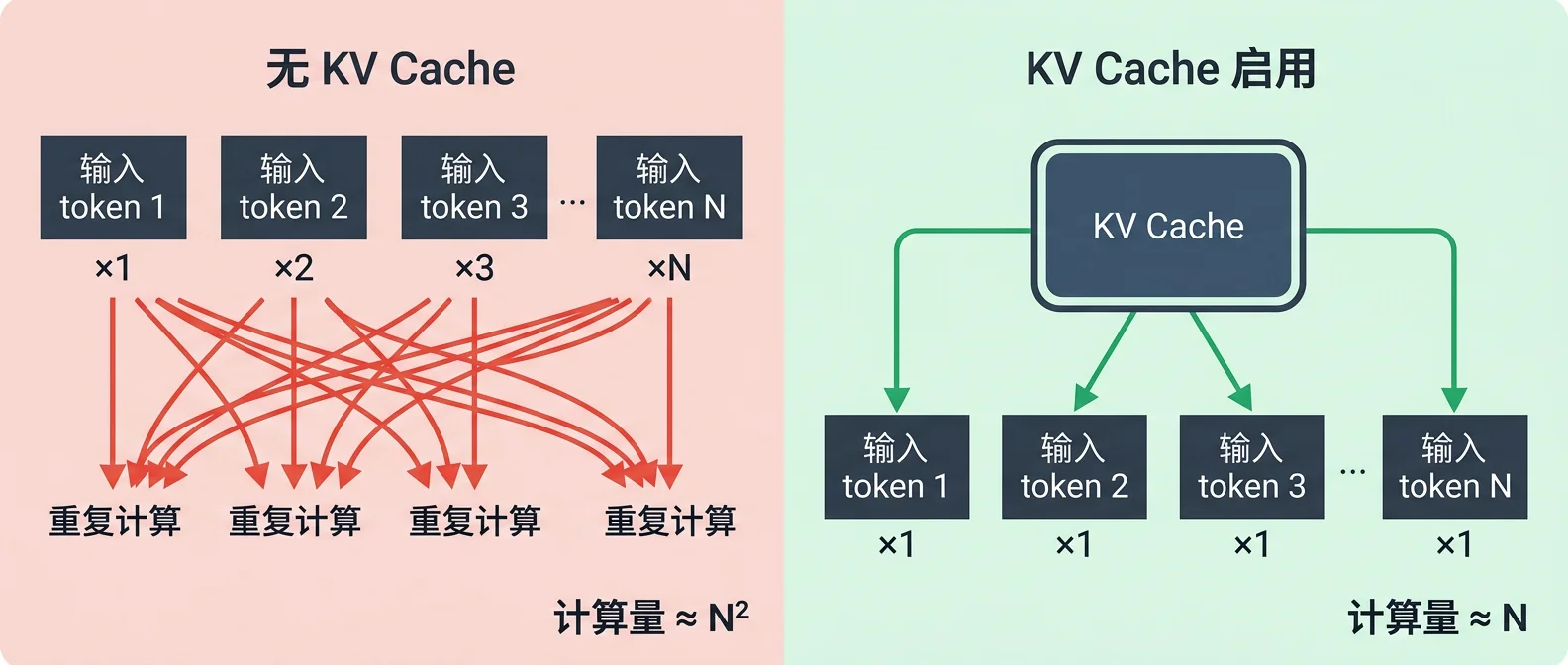
没有 KV Cache 时,对话越长,计算量增长得越快——不是线性增长,而是接近平方级。几千字的对话跑下来,等待时间会让人崩溃。
KV Cache 解决了什么问题?
KV Cache 的核心思路非常直觉:已经算过的东西,就不要再算第二遍了。
在模型内部,处理每个字的时候会产生一些中间计算结果(技术上叫做 Key 和 Value,简称 K 和 V)。这些结果有一个重要特性——历史内容的计算结果永远不会变。不管后面生成了什么新内容,“今天”这两个字的内部表示始终是固定的。
KV Cache 就像一位经验丰富的客服。上班前熟读产品手册后,面对第一个客户能直接回答,第二个、第三个也不用重新翻找——知识已经在脑中,随取随用。
这样一来,模型每一步只需要处理最新的那个字,其余的直接从缓存里读取,速度大幅提升。
这对你意味着什么?
作为一个日常使用大模型的人,KV Cache 带来的影响是实实在在的。
回复更快了。有数据对比显示,在相同条件下,有 KV Cache 的模型生成一段内容只需约 9 秒,而没有 KV Cache 则需要将近 40 秒。这还只是一段话的差距——对话越长,优势越明显。
长对话不会越来越卡。和 AI 聊了很久之后,它的反应速度并没有明显变慢。如果没有 KV Cache,随着对话字数不断积累,每次生成新内容的计算量会呈平方级增长,聊到后面会慢得让人崩溃。
复杂任务成为可能。让 AI 分析一份长篇报告、处理一本书的内容、进行多轮深度讨论——这些任务之所以能在合理时间内完成,KV Cache 功不可没。
代价与取舍

既然 KV Cache 这么好,为什么不让它缓存无限多的内容?
缓存需要占用内存,这是关键限制。
每缓存一个字的计算结果,都需要占用一定的显存空间。显存空间就像有限的办公桌面。桌面越大,能同时摆放的文件越多,但终究有上限。缓存内容太多,空间就会告急。
对于大型模型来说,这个开销相当可观。每个 token(大约对应半个到一个中文字)的缓存大约占 2.5 MB 的空间。一段几千字的对话,缓存就可能占用十几 GB 的显存——相当于同时把十几部高清电影的数据量压进内存里。
这也解释了一些你可能遇到过的现象:
- 为什么 AI 有”上下文限制”?不是模型”记性不好”,而是显存空间有限,超出限制后旧内容就会被清掉,给新内容腾地方。
- 为什么支持更长对话的模型更贵?更大的缓存空间需要更好的硬件,成本自然更高。
- 为什么同时使用 AI 的人越多,速度有时会变慢?每个用户都需要独立的缓存空间,人越多,资源越拥挤。
对于开发者来说,KV Cache 还有一个非常实际的好处——直接降低成本。
比如一个 AI 客服机器人,每次启动对话都会先加载一段固定的系统提示词。如果没有开启 KV Cache,每当一个新用户发来消息,模型就要把这段提示词从头计算一遍。高峰期几百个用户在线,这段提示词就要被重复计算几百次。
开启 KV Cache 之后,系统提示词的计算结果会被缓存下来,所有用户共享。后续每次请求,模型只需处理用户新增的内容。许多模型服务商对命中缓存的 token 收取更低的费用,甚至免费。系统提示词越长、调用量越大,省下来的钱就越多。
这个道理同样适用于法律咨询助手的条款库、医疗问答机器人的诊疗指南、教育平台的课程知识库——只要系统提示词是相对固定的,KV Cache 就能发挥作用。
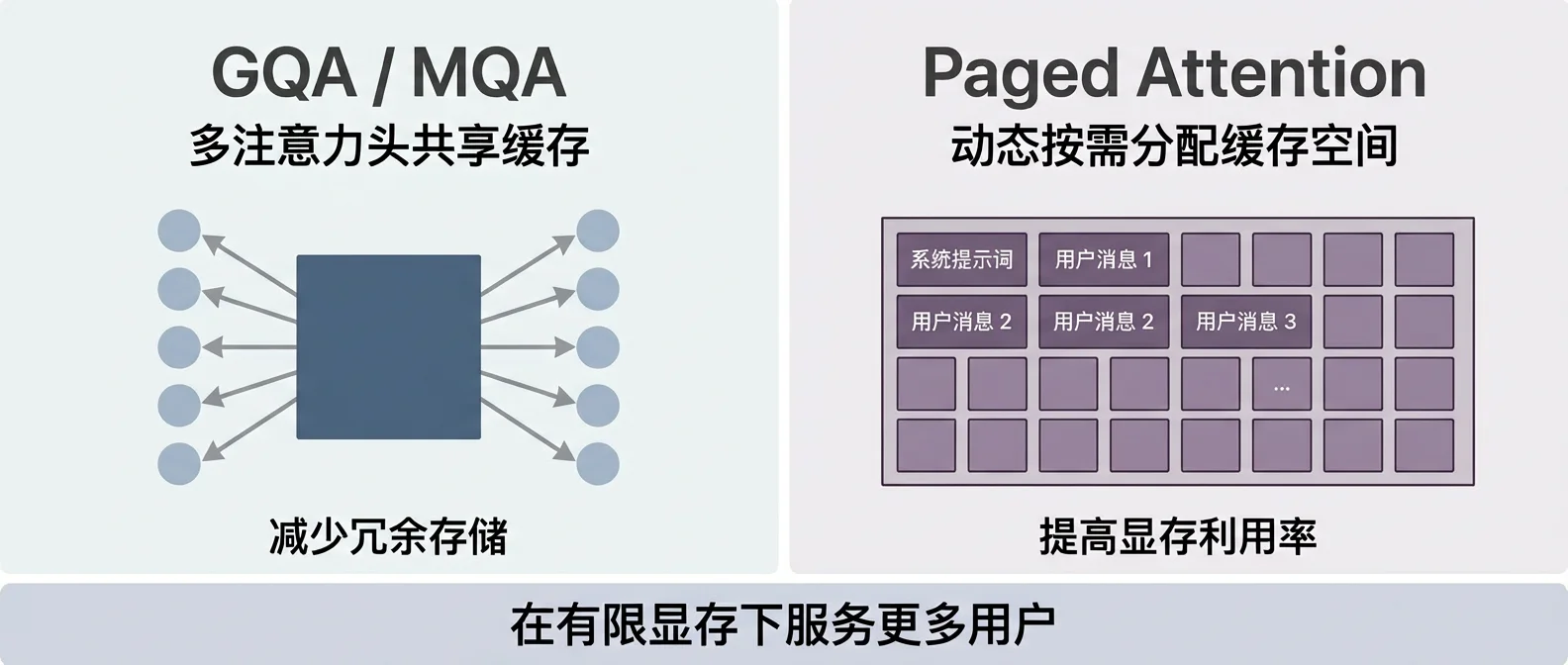
面对显存压力,技术团队也在不断优化。一个思路是让多个”注意力头”共享缓存(GQA / MQA),用更集约的存储方式减少空间占用。另一个思路是更聪明地管理缓存空间(Paged Attention),动态分配让有限的资源服务更多用户。
正是这些持续的优化,让今天的 AI 产品能在合理成本下服务大量用户。
KV Cache 本质上是一种用空间换时间的策略——把已经算过的中间结果存起来,避免重复计算。它不是什么黑科技,就是不做无用功。
版权声明
- 作者
- XingKaiXin
- 标题
- KV Cache:为什么 AI 回复越来越快?
- 发布时间
- 2026年3月24日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。