AI 写的测试全绿了?你在跟它一起自欺欺人
AI 写的测试全绿了?你在跟它一起自欺欺人
上个月我让 AI 给一个 Chrome 扩展加个功能:把网页上选中的文本发到侧边栏做翻译。需求不复杂:监听选区变化,抓取文本,传给侧边栏组件渲染。
写完之后我让它补测试。跑了一遍,全绿。空选区、重复选区、特殊字符、跨段落选取,都有。合并了。
几天后我自己用的时候发现不对劲。打开一个长页面,随便选了几段文字,浏览器开始卡顿。打开 DevTools 一看,选区事件每秒触发几十次,每次都在做 DOM 遍历和消息传递,CPU 直接拉满。
回去看代码:AI 在 selectionchange 上直接挂了处理逻辑,没有做任何防抖。看测试:每个用例都是单次选取、立即断言。代码和测试共享着同一个假设:选区事件不会高频触发。
我让它补一个防抖测试。它加了。跑了一遍,绿了。但看测试代码,它模拟的是”等 300 毫秒再选一次”,不是”300 毫秒内触发几十次”。我换了几种提示——“模拟高频触发""模拟用户在长页面随机拖选”——它都能写出来。但没有一个场景是它自己想出来的。全是我的描述翻译成的测试代码。
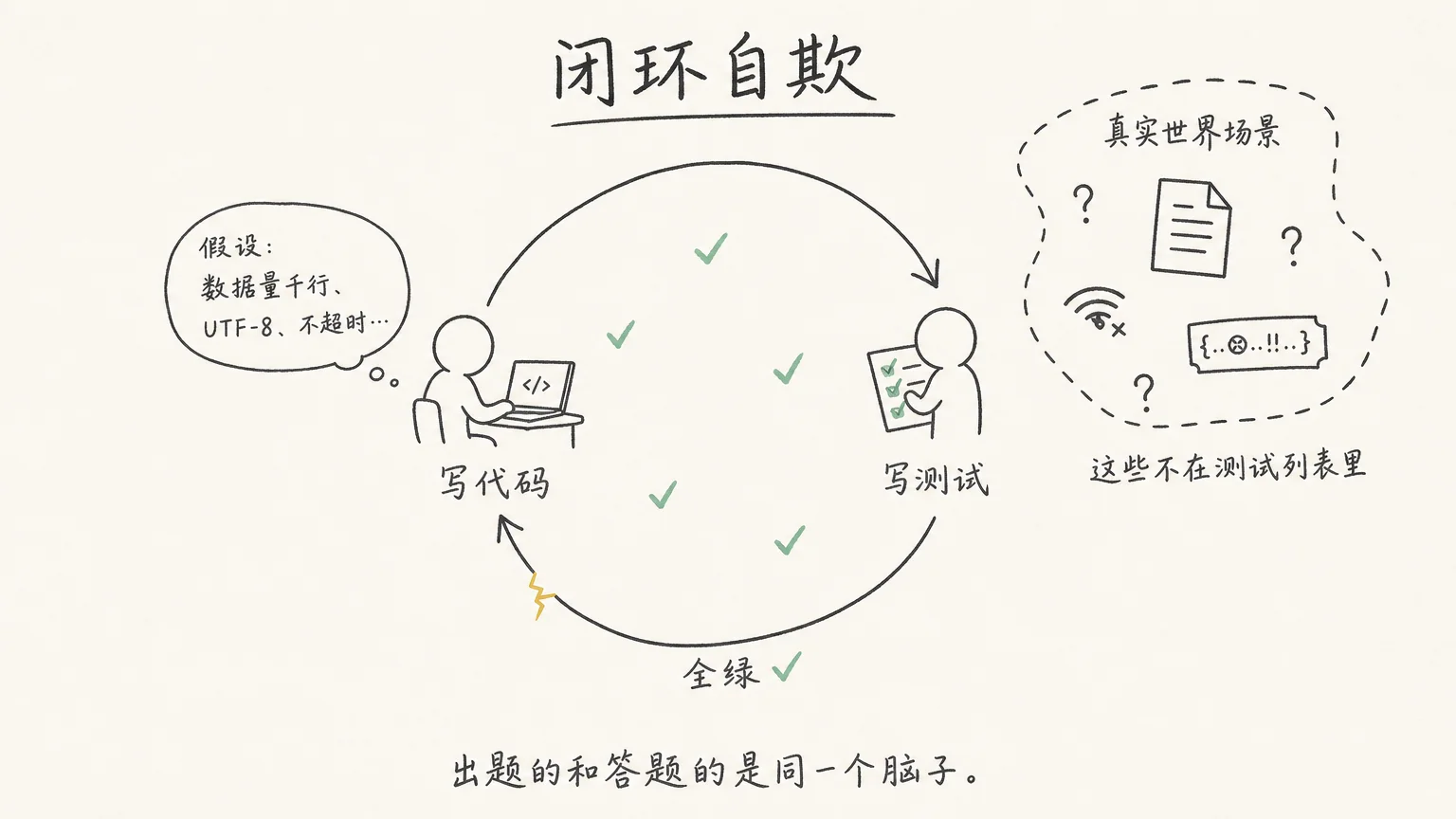
同一个脑子出的题,同一个脑子答的
测试为什么有用?因为它带着不同的视角。写代码的人在想”怎么让它跑通”,写测试的人在想”怎么让它挂掉”。同一段逻辑,两种思路对照,盲区才会暴露。
但 AI 同时写代码和测试的时候,这个角度差就没了。
AI 写代码时会做一组隐含的假设:数据量在千行级别、输入编码是 UTF-8、网络请求不会超时、并发不超过单进程能处理的量。这些假设你在注释和文档里都找不到,连你自己可能都没意识到它们的存在。但它们决定了代码里每一处具体选择。用内存加载,不用流式读取;用同步调用,不用异步队列;字符串直接拆,不做编码检测。
然后你说”写测试”。AI 基于刚写完的代码去构造用例。它不会构造一个反驳自己假设的测试,因为在它眼里,那些假设就是事实。代码不是为 50MB 设计的,测试里就不会出现大文件;实现里没有超时处理,测试就不会去模拟网络中断;代码是单线程的,并发场景根本不在考虑范围内。
出题的和答题的是同一个脑子。测试全绿只证明 AI 跟自己没有矛盾,证明不了别的。
覆盖率是个障眼法
更容易让人放松警惕的是覆盖率数字。
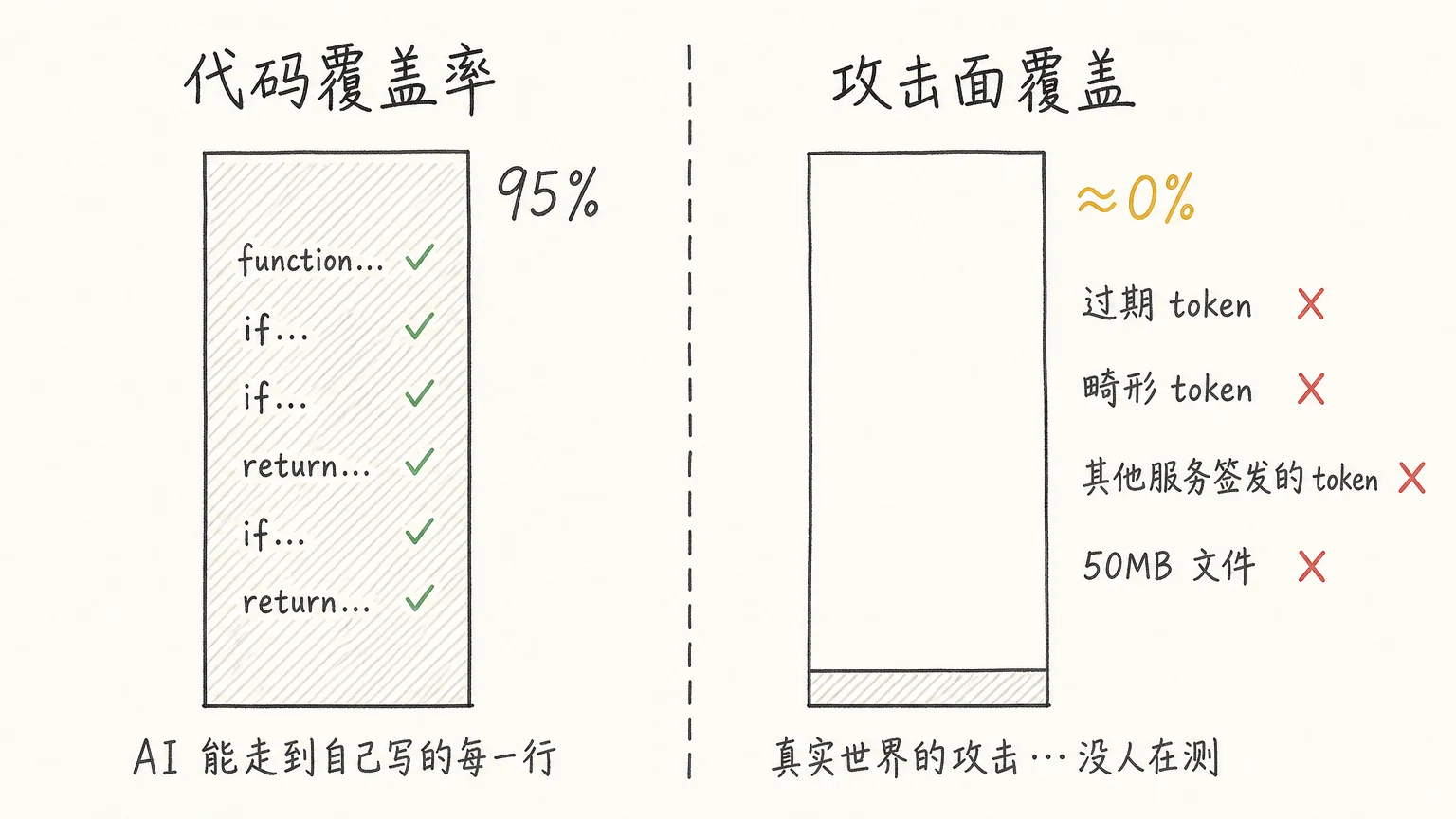
89% 看起来很安全。但覆盖率衡量的是”多少行代码被测试执行过”。多少真实场景被覆盖了,这个数字管不着。一行代码被走过,只说明在 AI 构造的那组输入下它被执行了。
AI 特别擅长刷这个数字。它知道代码有哪些分支、哪些条件判断,能精确构造数据命中每一行。最后数字很漂亮,但走的全是它自己预设的路径,没有一条是从你的业务场景倒推出来的。
我见过一个覆盖率 95% 的认证模块,所有测试用的 token 都是有效的、格式正确的。没有一个测试用过期 token、畸形 token、或者另一个服务签发的 token。95% 的覆盖率,0% 的攻击面覆盖。
AI 能做到的是把它自己写的每一行都走到。它做不到的是从外部视角构造它没想到的场景。
绿灯给你的安全错觉
32 个测试全绿。一条绿色进度条,89% 覆盖率。
我承认看到这个画面的时候,我自己的警惕性会下降一档。绿灯是一个非常强的视觉信号,它在说”安全”。哪怕我打算继续审查,心理上的状态也从”还在找问题”切到了”已经被验证了”。
这里有个认知陷阱。这些测试确实是”对的”。声称测空文件,确实测了空文件;声称测格式错误,确实测了格式错误。每一条都在做自己说要做的事。你挑不出毛病。
但测试做了什么,和它没想到要做什么,是两件事。盲区从来不在测试列表里。你看着一排绿灯,根本不会去想:除了清单上这些,还有什么不在清单上?
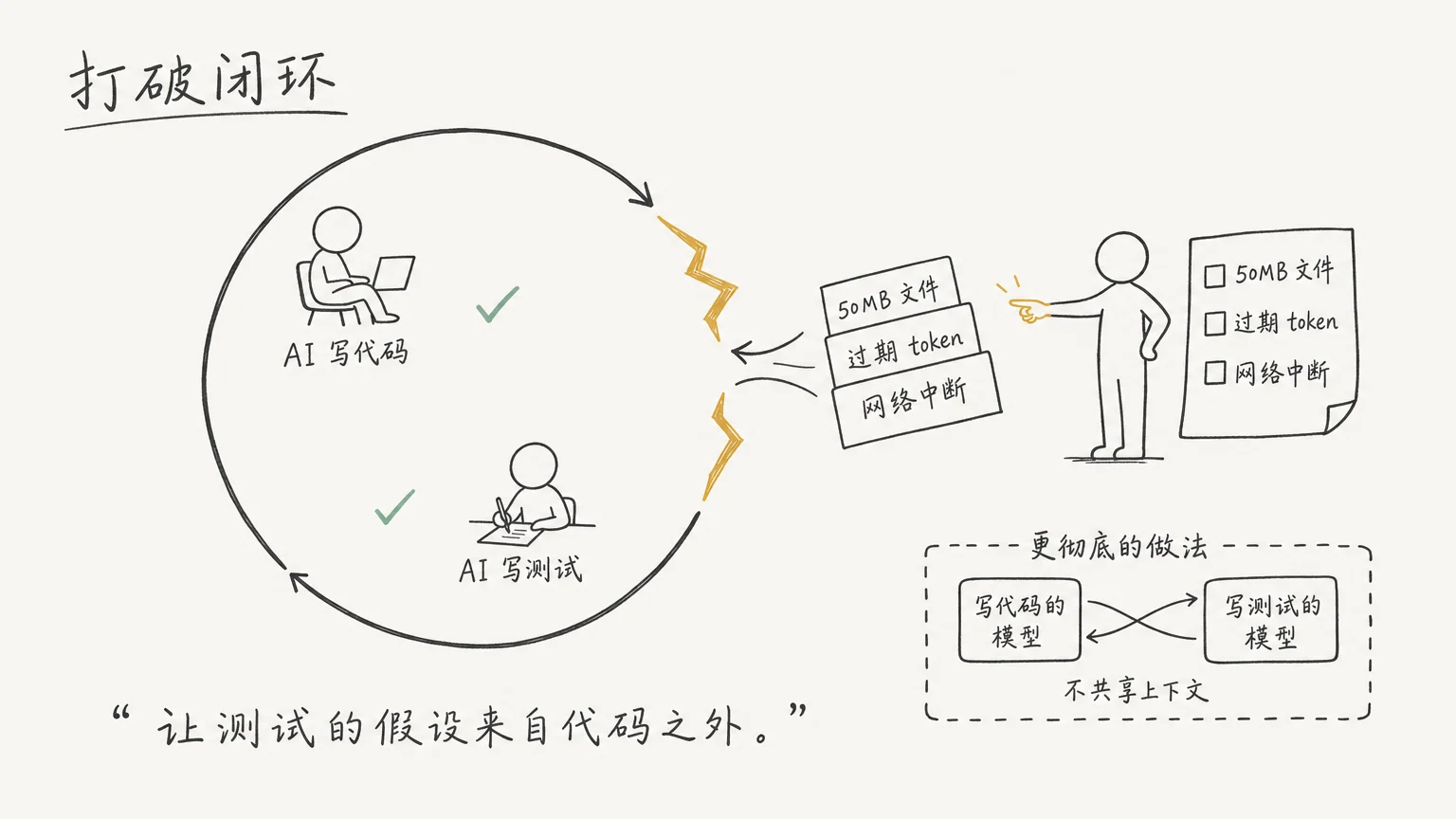
打破闭环
你不会让同一个人既出卷又答卷,然后拿成绩证明他学会了。考试有效,靠的是出题人和答题人之间的知识不对称。出题人知道哪里容易错,答题人不一定知道。
AI 同时写代码和测试就是考生兼考官。它的测试只回答一个问题:“代码按我的理解跑通了吗?“代码在真实世界里能不能活,没人问。
打破这个闭环只有一个方向:让测试的假设来自代码之外。我后来的做法是,场景由我来定,AI 只负责把场景变成可执行的测试代码。我告诉它:用 50MB 文件测导入、用过期 token 测认证、模拟导入到一半网络断开。这些场景从我踩过的坑和对业务的理解里来,AI 不知道这些坑长什么样。两套假设不再是同一套。
如果要更彻底——我自己还没到那一步——让写测试的模型和写代码的模型不共享上下文。写代码的模型做了哪些假设,写测试的模型不知道,它只能从需求描述出发推演什么情况下可能出问题。不保证全抓到,但至少不是自己考自己。
回到开头的问题,模块修完之后我加了一个测试:在一个有二十几个 tab 的浏览器里连续快速选取。这个场景不是 AI 想出来的,是被自己用卡了教出来的。
下次测试全绿的时候,先看一眼测试列表,问一个问题:这些场景,是 AI 从它自己的代码里推出来的,还是你从你自己的系统里推出来的?
如果都是前者,那 32 个绿勾证明不了什么。
版权声明
- 作者
- XingKaiXin
- 标题
- AI 写的测试全绿了?你在跟它一起自欺欺人
- 发布时间
- 2026年6月4日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。