
我让 AI 审了自己的代码,审了 10 轮
我让 AI 审了自己的代码,审了 10 轮
3 月 28 日,周六上午 8:32,我跟 Codex 进行到第 4 轮代码 review。
我打了一段话给它:
我们就已经做了好几轮重 review 了,但好像总能发现新的问题。
这句话本来是一句疑问,但我打完之后发现,它其实是这篇文章的核心。
为什么 AI 在自己刚刚 review 过的代码里,反复能找到新问题?这件事,直到我自己做完 10 轮才看明白。
而且看明白之后,我对”AI 审 AI”这件事的态度,反而比开始之前更乐观了 —— 但也比开始之前更知道它的边界在哪里。
这是什么项目,以及我为什么会做 10 轮 review
简单交代背景:这是一个我自己写的命令行工具,用来查询公司内部的金融数据接口。Python + Typer + uv,一个比较典型的 Python CLI 工程。
3 月 5 号开工,3 月 12 号主体功能就写完了 —— 8 天时间,跟 Codex 进行了 39 个会话。然后我把它放下了 16 天。
为什么要放?因为我相信代码也需要”沉淀”。那 16 天里我自己在用它查数据、调接口、踩自己埋的坑。这些使用体验是新的输入。
到 3 月 28 号那天上午,我决定回头审一遍。从早上 7:49 开始,到中午 10:18,总共做了 10 轮 review。每一轮我用的是同一句 prompt:
$friendly-python $piglet review代码,模块拆分不合理,单体大文件,圈复杂度高。$friendly-python 和 $piglet 是两个 python 相关 skill —— 一个偏边界与变更点的判断,一个偏分支展开和条件收口的判断。把它们组合起来,就是我这次 review 的”标尺”。
注意:我没有每次换 prompt。这是一件刻意的事。
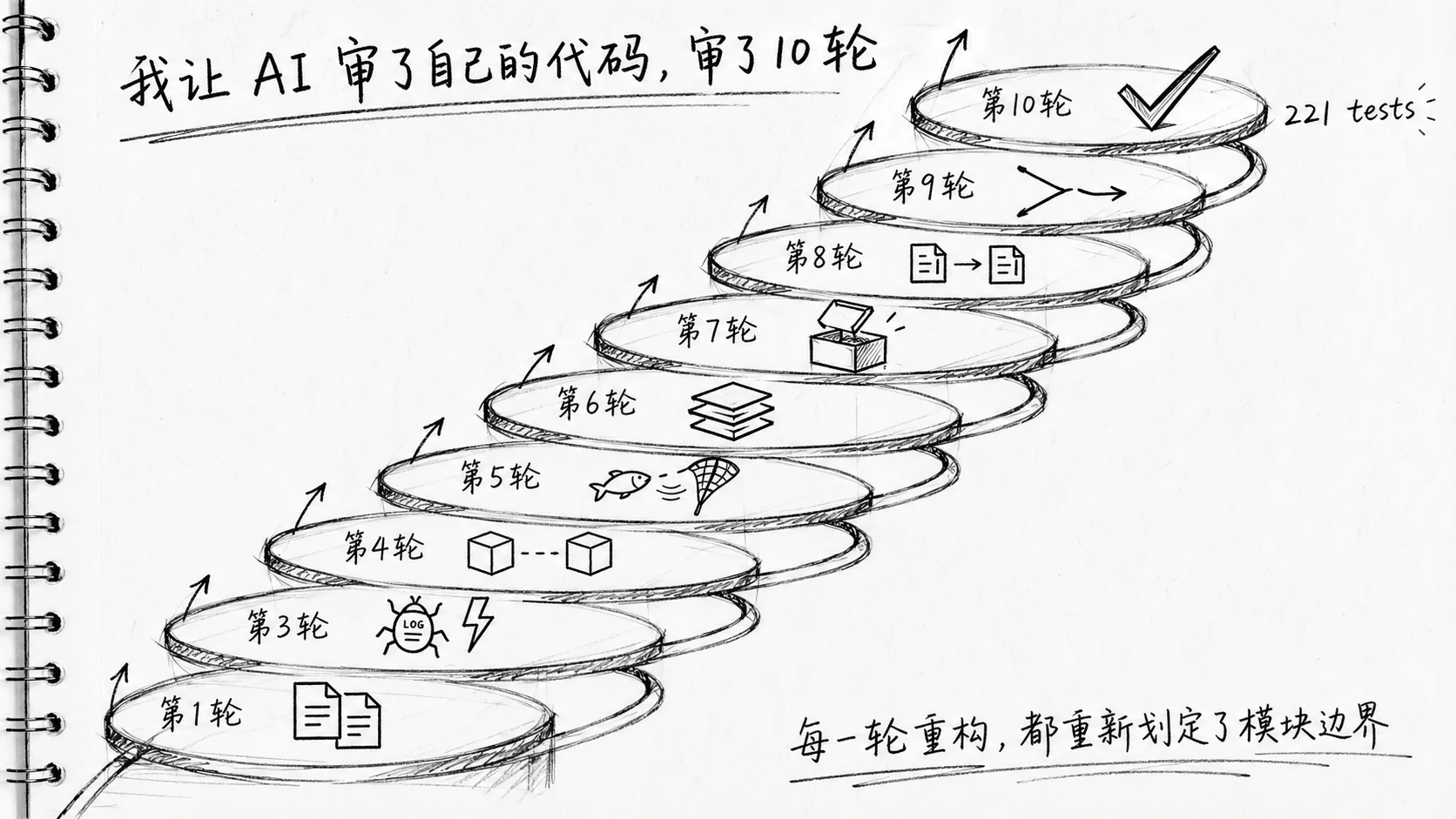
第 1 轮:它先找到了”重复的渲染骨架”
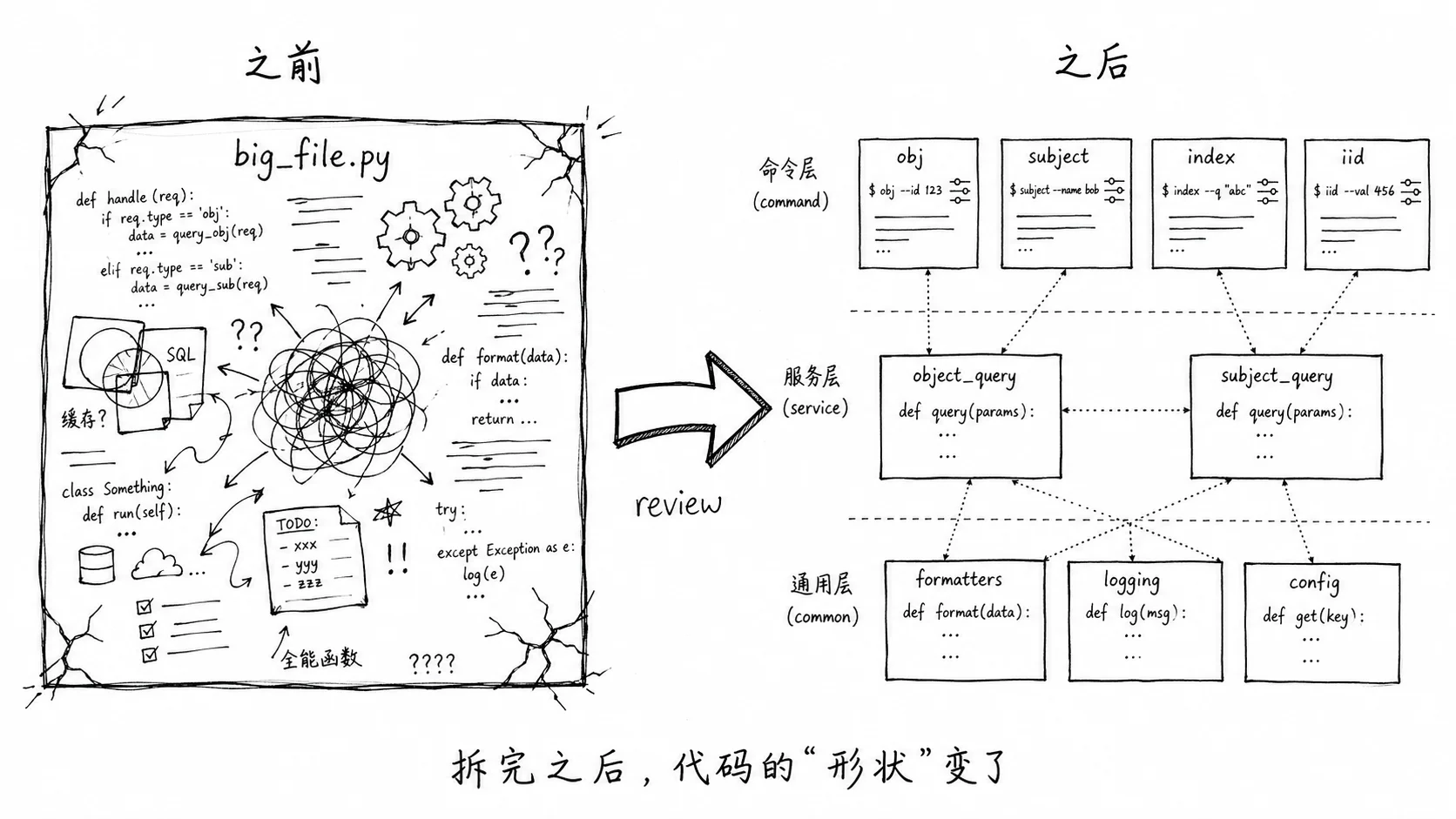
第 1 轮 review,Codex 先用 wc -l 和分支数量量了一下整个仓库,定位到了三个命令文件 obj.py、subject.py、index.py。
这三个文件实现了 obj、subject、index 三个查询命令。每一个命令都要支持 JSON、CSV、Table 三种输出格式;每一个命令也都要做用户名缓存、render 统计。
Codex 在 review 报告里说的是这件事:这三个文件里,大约 60% 的代码在做同样的事情,只是换了不同的 service 来调。
它的方案是:抽出一个 commands/_common.py,把这三个命令的”输出渲染”和”统计上报”合并成一份。各自的命令文件只保留参数定义和 service 调度。
这一轮我看完它的方案,觉得没问题,让它执行。它改完之后跑了完整测试,210 个测试全过。
我以为这一轮收尾了。
第 2 轮:它把自己刚埋的雷,自己挖了出来
第 2 轮我又用同一句 prompt 起了一个新会话。这一次它扫到的”大文件高复杂度”和上一轮不太一样,我让它”按它发现的问题做计划,然后逐步实施”。
它做了一组拆分,然后跑测试。出问题了:
FAILED tests/unit/test_output_formatters.py::
test_build_table_from_response_respects_select_order_and_shows_sort
- RecursionError: maximum recursion depth exceeded
1 failed, 209 passed in 1.47s210 个测试,过了 209 个,挂了 1 个。RecursionError。
我把这段失败信息丢给 Codex,让它自己定位。它去翻了 formatters/table.py,然后跟我说了一段我没想到的话:
问题在
table.py的时区兼容钩子。我之前为了兼容测试里的 monkeypatch,把table_rendering的时区实现回指到了 facade 层,但默认分支又绕回了包装函数本身,导致DateTime渲染路径里递归。
这段话翻译成人话就是:第 1 轮它为了不搞坏测试,写了个兼容钩子。那钩子平时不走,测试碰不到。第 2 轮一动上下文,正好踩上去了。然后它自己,在第 2 轮里,把它挖了出来。
修复也是它自己写的。修完之后 210 个测试全过。
我在这里愣了一下。
我们都知道 AI 写代码会出 bug。我们也都听说过”AI 不会修自己的 bug”这种说法。但这一刻我看到的事实是:AI 第 1 轮埋了一个雷,AI 第 2 轮自己审出来这个雷,AI 自己修好了。
整个过程里我做了什么?我把测试失败信息原文复制粘贴给它了。仅此而已。
第 3 轮到第 4 轮:每一轮都有完全不一样的发现
我列一下接下来几轮 Codex 找到的具体问题,用同一把 prompt 量出来的:
- 第 3 轮(8:21):日志层
logging_setup.py里把日志配置、格式化、状态管理、工具函数四件事挤在一个文件里,需要拆成logging_state.py / logging_formatter.py / logging_utils.py / logging_setup.py四个职责明确的模块,主文件做 facade - 第 4 轮(8:32):服务层职责混装,
query_service.py既要管 obj 查询又要管 subject 查询,需要拆成object_query_service.py和subject_query_service.py,共享部分抽到query_payloads.py - 第 5 轮(8:49):前几轮拆完命令层骨架,我以为齐活了。Codex 一扫:等等,漏了一个
iid.py。这个命令还是老写法,没对齐新骨架。我那一刻有点泄气——前面明明已经统一过了,怎么还有漏网之鱼?Codex 的回答是:前几轮注意力都在拆大文件,这个文件小,优先级不够高,被忽略了。它不是没审到,是”排不上号”。 - 第 6 轮(9:03):
index/subject的命令文件,可以再拆成”薄入口 + 解析 + 执行”三层
到第 4 轮的时候,我打了那句话给它:“我们就已经做了好几轮重 review 了,但好像总能发现新的问题。”
它没有给我那种”AI 是越审越好的”鸡汤回答。它给我的回答大致是这个意思:
因为每一轮重构,都重新划定了模块边界。新的边界产生新的接缝,接缝处会暴露上一轮在旧结构下”看起来合理”的设计。这不是 review 不到位 —— 这是结构本身在演化。
我盯着这段话看了两遍。
它说的是一个非常简单的道理:review 不是一次性活动,是迭代的。你重构完之后,代码的”形状”变了,原本被掩盖的问题就会暴露。原本 OK 的设计,在新形状下可能就不 OK 了。
这个道理我当然以前就知道。但我没意识到的是:AI 审 AI 这件事,正好天然契合这个迭代逻辑。因为 AI 不会”已经审过这块了所以不审了” —— 它每一次都从头看,每一次都按你给的标尺重新量。
第 7 轮到第 9 轮:其实我已经想停了
第 7 轮(9:34)的时候,我心里其实开始打鼓 —— 是不是该停了?6 轮已经做了很多重构,代码已经比 8 天前主体完成时干净很多。再审下去,会不会变成无意义的折腾?
但我还是又跑了一轮。
这一轮 Codex 找到的是 config_store.py —— 一个一直在”看起来还行”的文件。它把值的序列化、coercion(类型转换)、扁平化、层合并和 dotted key 判断,五件事堆在一个 ConfigStore 类里。前 6 轮 review 没动它,因为前 6 轮在拆别的地方,这个文件相对就显得”还行”。
到第 7 轮,前面拆得差不多了,这个文件就变成了仓库里”剩下最重的”。
第 7 轮拆完之后,我又起了第 8 轮。
第 8 轮找到了一件更细的事:查询摘要这个东西在三个 formatter 里被各自实现了一遍。每一个 formatter 都自己写了”条件渲染、logic 展开、排序字段解析”。前 7 轮没注意,因为前 7 轮在看”文件太大”这种问题,这个事是”逻辑重复”,在不同文件里,单个文件不大。
第 9 轮找到的是 where/cond 解析在 command 层和 service 层各写了一份规则,需要统一真源。
到这里,我承认它每一轮都在找新东西,而且每一轮找到的”新东西”在前一轮的视角下确实看不出来 —— 不是 AI 偷懒,是结构演化让新的问题浮出水面。
第 10 轮:just isok 通过
第 10 轮上午 10:06,我让 Codex 跑了我的”全量验收”命令 just isok —— ruff、pyright、ty、pytest 全部跑一遍。
结果:221 个测试全过,覆盖率 92%。
注意这个数字:第 1 轮开始的时候是 210 个测试。10 轮之后变成 221 个。多出来的 11 个测试,是 review 过程里 AI 自己补上的回归测试 —— 它每一次发现新边界,会顺手补一组针对性测试,锁住这次发现。
到这一刻我突然想明白一件事:这 10 轮 review 的产出,不只是”代码变好了”,还包括”测试变多了”。AI 在每一次审视过程中,都在把它的发现固化为可追踪的回归测试。
这是我之前没预期的副产品。
下午我又起了一个会话(第 50 个),让它根据最新代码更新 README 和 AGENTS.md。这个项目的 3 月 28 日,到这里收尾。

那么”AI 审 AI”到底靠不靠谱
回到开头那个问题。我现在的判断是这样的:
AI 审 AI 不是”发个 prompt 让 AI 看一眼”。 它需要三样东西同时在线:一把稳定的尺子($friendly-python $piglet)、把尺子反复量的耐心(10 轮,2.5 小时)、以及发现之后真能改的执行力。光看不改,等于零。
AI 在某些事上比人强,但”什么时候停”必须人说了算。 它没有”这块我刚看过”的疲劳,也不会偷懒不跑测试。但 AI 理论上能无限审下去,每一轮都还能找新东西。值不值得修、修到什么程度,这是你的判断。我第 7 轮其实想停,但我赌了一把;第 10 轮我决定停。这两个决定都不是 AI 给的。
真正值钱的,是你那把尺子。 那两个 skill 不是临时写的,是慢慢磨出来的。AI 默认的 review 视角太泛,基本等于没 review。先花时间想清楚——你希望 AI 用什么标准量你的代码。这个标准写出来,才是起点。
最后一件事

那天晚上我截了一张 git log 的图,从 3 月 5 号到 3 月 28 号,主体功能 8 天写完,然后 16 天空白,然后 3 月 28 号一天 11 个 commit。
我盯着那张图看了一会儿。
主流叙事告诉你,用 AI 写代码要快。但我的 10 轮 review 说明了一件事:快的是写,慢的是审。大多数人把审的时间省了,这不是效率,是欠债。
那 16 天也不是空白。我在用它查数据、踩坑、让代码沉淀。没有这个沉淀,3 月 28 号那 10 轮 review 根本审不出东西。
下一篇写那 16 天——没有那 16 天,这 10 轮就是空的。
版权声明
- 作者
- XingKaiXin
- 标题
- 我让 AI 审了自己的代码,审了 10 轮
- 发布时间
- 2026年4月30日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。