
跑一下试试,是 AI 时代最贵的验收方式
跑一下试试,是 AI 时代最贵的验收方式
AI 给我写了一个日期格式化函数。测试全过,我扫了一眼,合并了。
三个月后要改日期格式化逻辑,改完上线,数据错乱。排查半天才发现:项目 utils 里本来就有一个功能几乎一样的函数,只是命名不同。AI 当时没复用,自己写了一个新的。我只改了 utils 里那个,AI 写的那个压根没碰,因为我根本不知道它存在。
从合并那天起 bug 就埋下了。测试全过,“跑了一下”什么都没看出来。
速度放大了验收的缺口
手写代码的时代,“跑一下试试”勉强说得过去——因为你写了什么你心里清楚,你知道哪些地方可能有问题,你的手动测试多少是有针对性的。
但 AI 写代码不一样。生成速度远超你阅读的速度,实现路径不一定是你预想的那条,没有明确说明的地方它会自己做判断。这些判断大多数时候合理,但不一定符合你的业务逻辑。
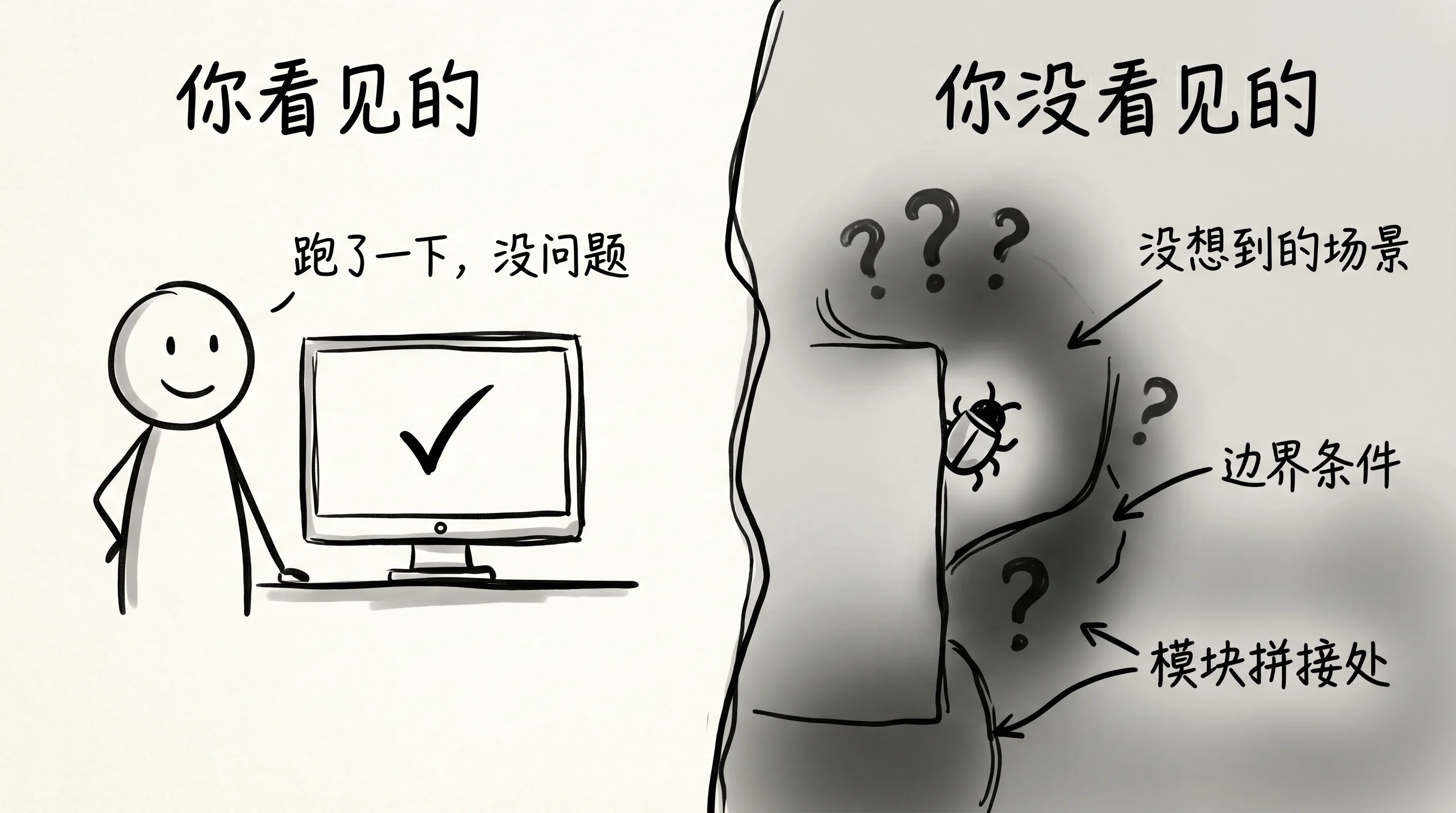
你”跑一下”测到的,是你想到的场景。你没想到的场景,就是漏洞藏身的地方。
更麻烦的是,Agentic 开发的节奏比手写代码快得多。你可能一个下午让 AI 写了三个模块,每个都”跑了一下”,感觉都没问题。但三个模块拼在一起,在某个你没有走过的路径上,问题才会出现。
速度越快,“跑一下”这个验收方式的漏洞就越大。
先写验收标准,再让 AI 写代码
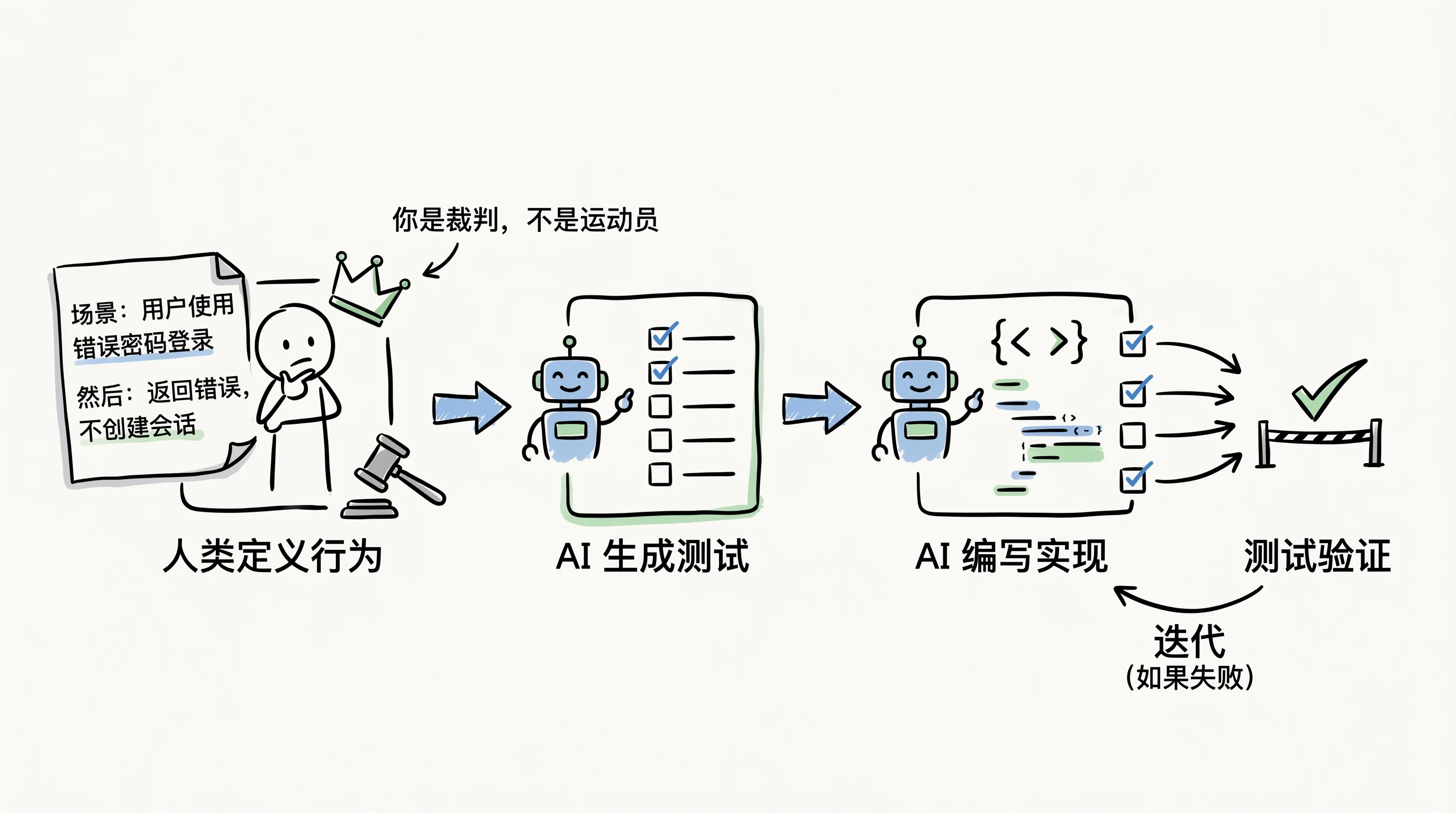
思路不新:写代码之前,先用人话把”什么算对”描述清楚。比如”用户连续输错密码 5 次,锁定账号 15 分钟”。这句话本身就是验收标准,产品经理能看懂,AI 也能看懂。
这个做法(BDD,行为驱动开发)在手写代码的时代一直推不动,工程师嫌先写行为描述再写实现太麻烦。但 Agentic 开发把成本结构改了:你写行为描述,AI 转成可执行的测试用例,再根据测试写实现,自己跑通验证。你唯一要做的判断是:行为描述写对了没有。
而且有一个反直觉的事实:让 AI 写测试,比让 AI 写功能代码更可靠。 测试的正确性比实现的正确性更容易被人判断。你看一眼测试用例,能直接判断它测的是不是你想要的行为;但你看一眼实现代码,很难判断它在所有边界条件下都是对的。
我自己的做法是,让 AI 生成测试之后,先花几分钟过一遍测试用例清单。不需要读测试代码本身,只看每条测试描述的是什么行为,少了哪个边界场景一眼就能看出来。这几分钟的回报率极高:在验收标准层面发现的遗漏,修复成本几乎为零;同样的遗漏等代码写完才发现,可能要推翻整个实现。
把验收标准前置,给 AI 一条有终点线的赛道。这是第一层验收的核心。
测试抓不住的那类问题
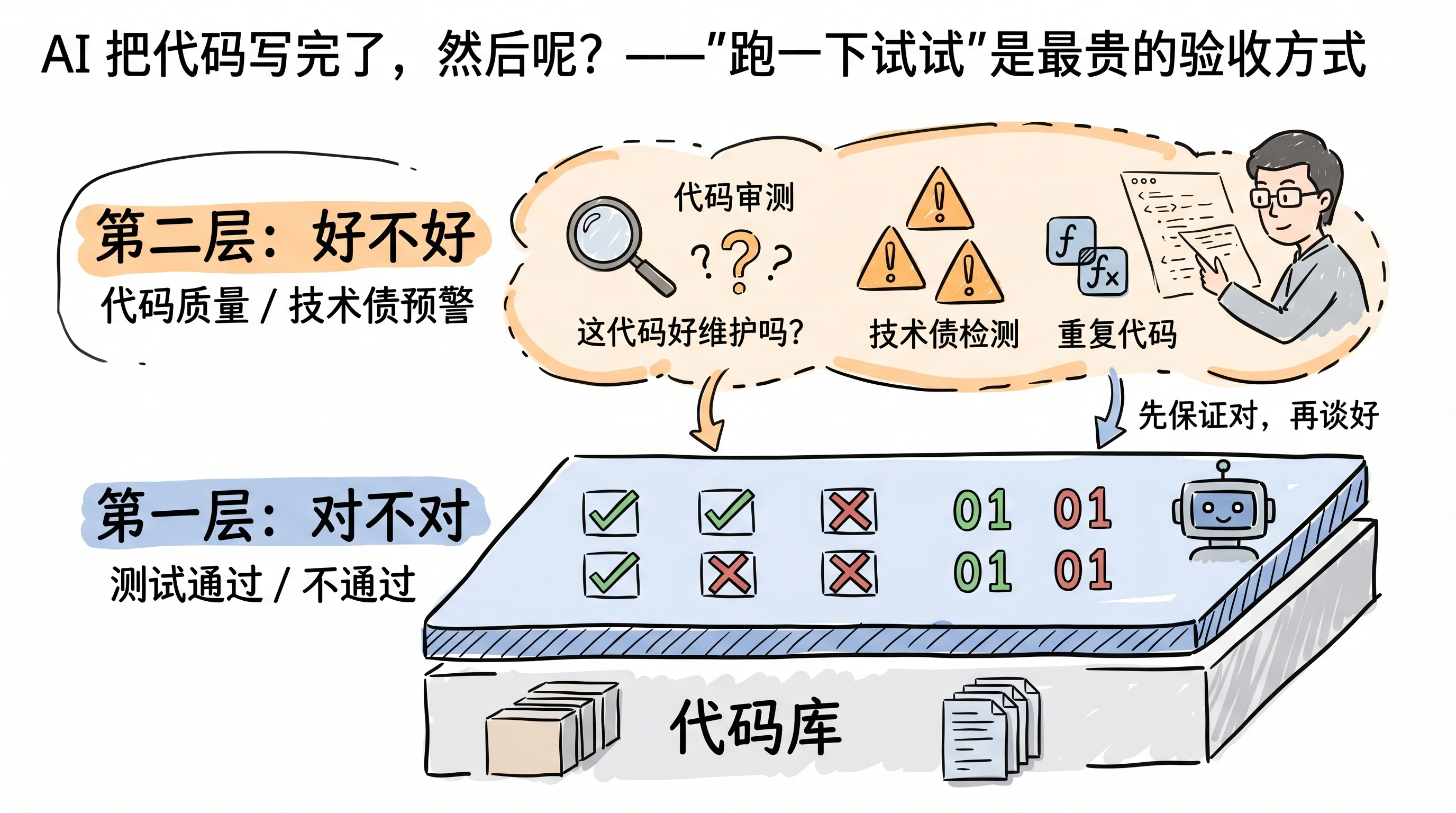
功能验收解决了”对不对”的问题,但还有一个没解决:质量。
AI 优化的目标是让当前测试通过,至于三个月后这段代码好不好改,不在它的考虑范围内。项目里明明有一个功能相似的工具函数,它会再写一个新的;错误处理只要不抛异常就算完事;代码风格跟项目其他部分对不对得上,也不是它操心的事。
这些问题单独看都不是大事。但它们累积起来就是技术债。今天不影响运行,六个月后每改一行都如履薄冰。
开头那个日期函数就是这类问题。每个函数单独看都是对的,测试全过。但两个功能重复的函数同时存在,改了一个忘了另一个,bug 就这么埋进去了。靠测试抓不住。
问题在于,质量没有标准答案,也没有一个分数可以打。你没办法跑一个命令,输出”质量:87分”。
但有一件事是可行的:让另一个模型来读这段代码。
功能 bug 应该被测试抓住,这里让它做的是另一件事:以”三个月后要接手这个项目的工程师”的视角读代码。哪些地方会让人困惑?哪些地方引入了不必要的复杂度?哪些地方和项目已有代码存在功能重复?
为什么要换一个模型?写代码的模型对自己的输出有惯性,注意力集中在”能不能工作”上。换一个没有这段代码生成历史的模型来读,更容易看到那些局部合理但整体有问题的地方。
我通常给评审模型的角色设定是:你要接手这个项目,读完这段代码后指出三类问题——和现有代码的重复或不一致、错误处理中被吞掉的异常、以及任何让你需要”想一下才能理解”的地方。这个聚焦的视角比泛泛地说”帮我审一下代码”有效得多,它不会花篇幅告诉你变量命名可以更好。
它发现不了所有问题,但能在技术债还是种子的时候看到它。早发现,修一下就好;晚发现,可能要推翻重来。
十分钟和两周
回到开头那个日期函数。如果验收标准里写了”复用项目已有的工具函数”,AI 不会另起炉灶写一个新的。就算漏了这条,让另一个模型扫一遍,和现有代码的重复大概率也会被标出来。
两层验收加起来多花十分钟。省掉的,是三个月后排查那个”明明测试全过啊”的 bug。
写代码变得很容易了。判断什么代码值得存在,才是越来越贵的能力。
版权声明
- 作者
- XingKaiXin
- 标题
- 跑一下试试,是 AI 时代最贵的验收方式
- 发布时间
- 2026年4月11日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。