你以为 Agent 在 debug,其实它在猜
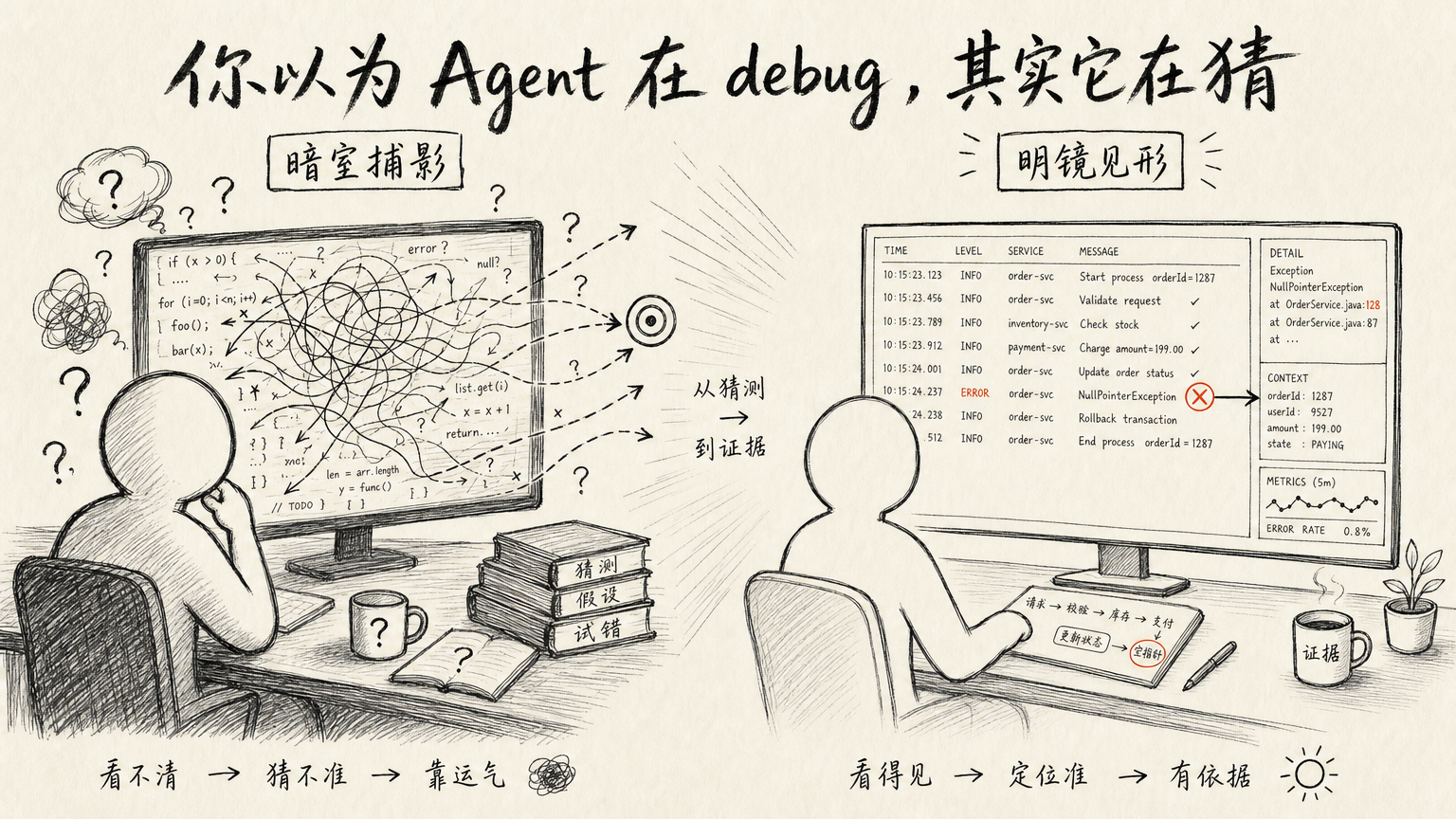
你以为 Agent 在 debug,其实它在猜
我第五次让 Agent 改同一个 bug。
它每一轮都很笃定:根因找到了,这次应该好了。然后我跑起来,报错照旧。
它的动作也很固定:读一遍代码,构造一套解释,改一版实现,等运行结果。失败之后,再构造一套新解释,再改一版。看着它一轮轮转,我突然意识到,它已经陷进了源码的内循环——在用静态文本想象一个动态系统。说白了,它不是在 debug,是在猜。
最近我在做一个本地小工具:worker 收集同一台机器上几个 coding agent 留下的会话,前端把它们聚合起来方便回看。排查这个工具自己的 bug 时,我看到一个很稳的规律——只要我不给运行时输出,Agent 就开始在源码里编假设;一旦我贴出几行日志,它通常很快就指出问题在哪。
决定 debug 质量的,不是它有多聪明,是它手里有没有程序真实跑起来之后的证据。
一次典型的”改错层”
举个刚发生过的。
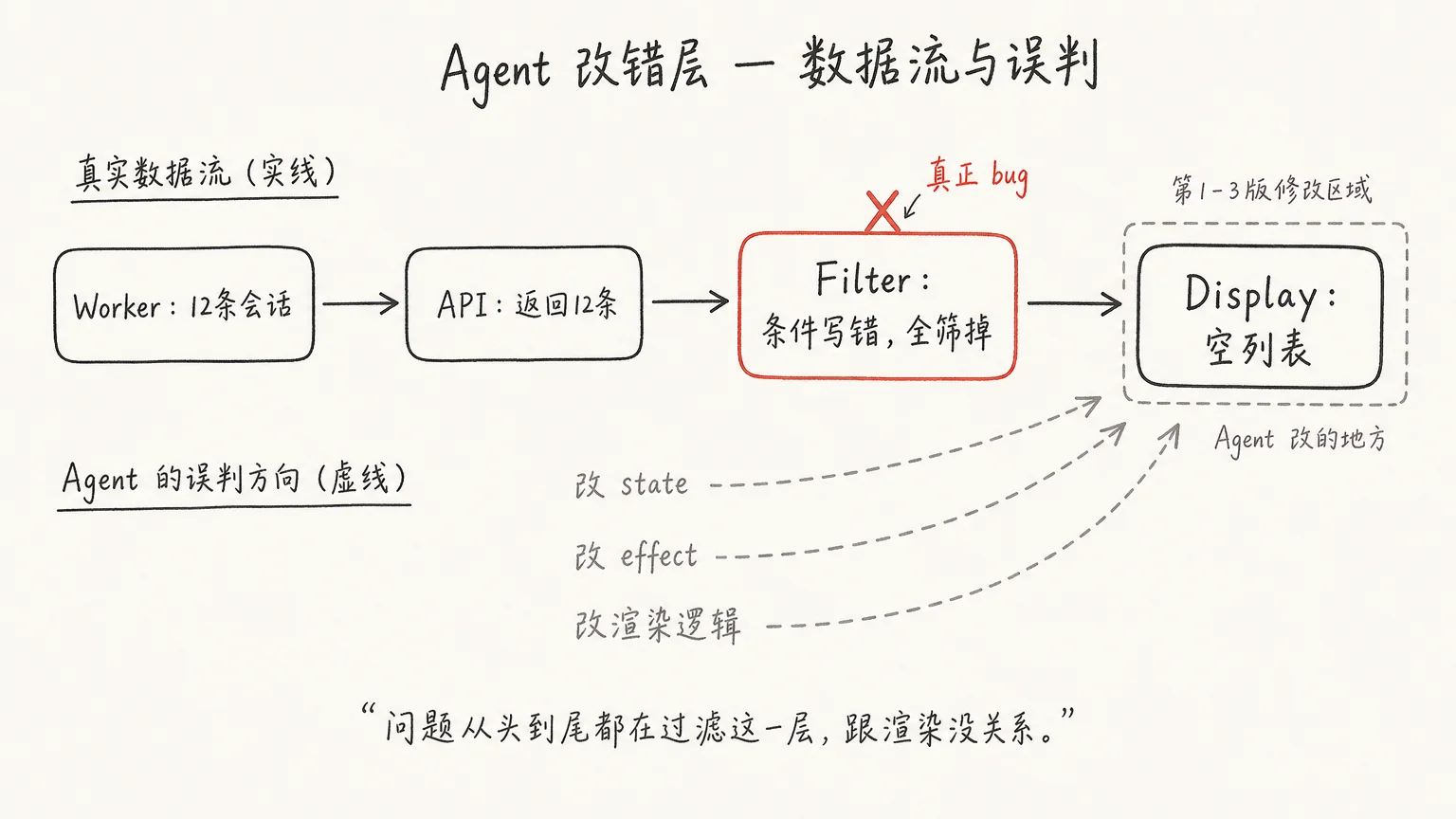
前端页面一直显示空列表。Agent 头几轮都在改渲染:一会儿怀疑 state 没刷新,一会儿怀疑 effect 依赖写漏了。改了三版,列表还是空的。
我让它停下,别改逻辑,先在三个位置打日志:worker 收到了多少条会话、接口返回了什么、前端过滤函数进出各是什么。我复现一次,把输出贴回去。
结论立刻翻盘:worker 已经拿到 12 条会话,接口也正常返回 12 条,前端在一个写错条件的 filter 里把它们全筛掉了。问题从头到尾都在过滤这一层,跟渲染没关系。前三版修改,全打在了错误的层上。
不是它笨。是它前三轮手里只有代码,看不到那 12 条数据其实已经到了前端。它一直在为一个错误的假设找补,而这个假设,一行日志就能推翻。
只给源码,它就只能做静态推理
把这事想清楚,得先看 Agent 的处境。
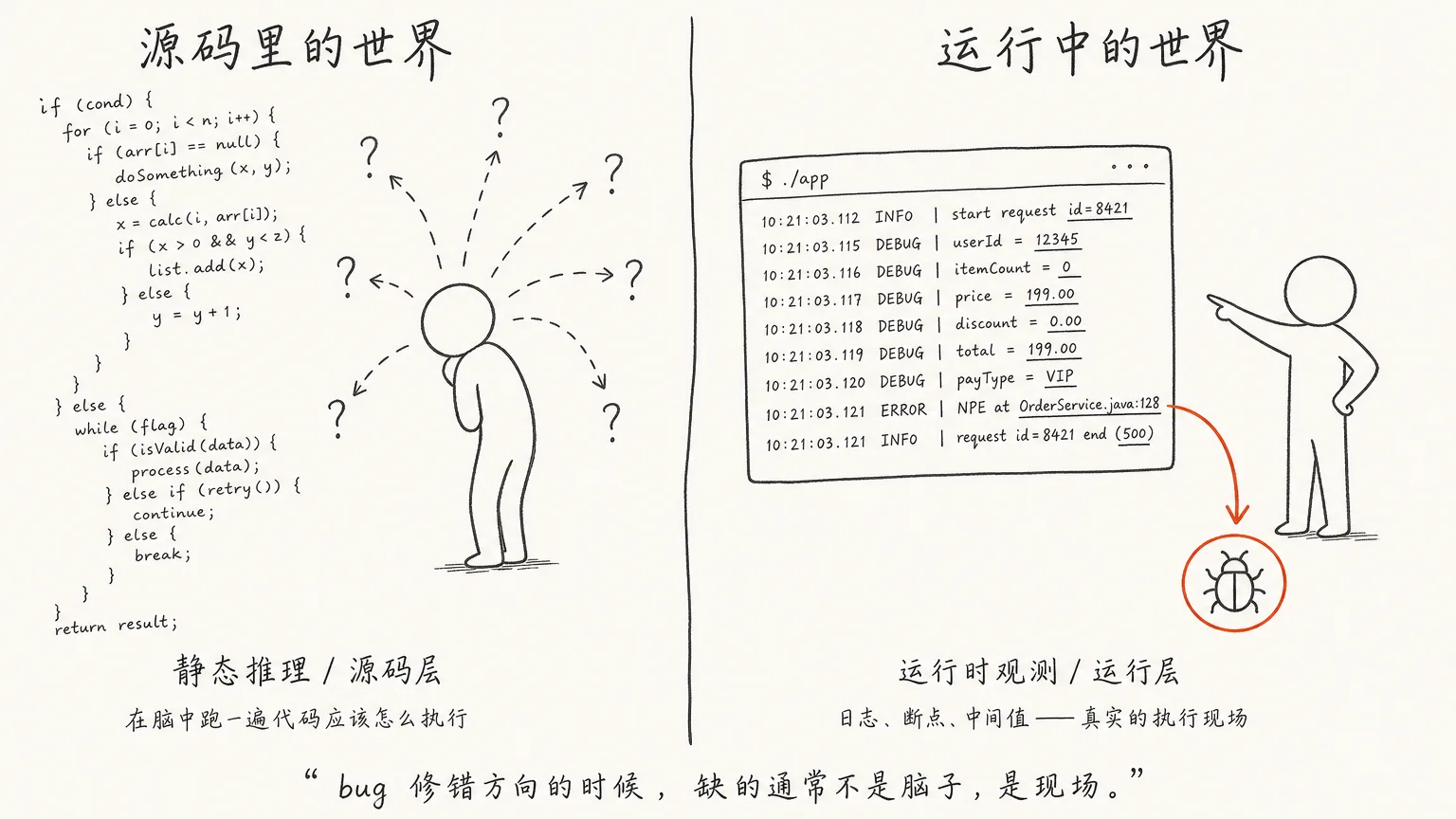
你让它改 bug,它能拿到的主要是代码:函数、调用链、类型定义。它读完,在脑子里跑一遍这段代码”应该”怎么执行。注意是”应该”——它做的是静态推理,对着不会动的文本想象一个会动的程序。
人也这么干。区别是,有经验的人卡住时会停下来拿现实校准:打个断点,print 一个中间值,翻一眼日志,看看脑子里那套执行模型是不是错了。
只拿到源码的 Agent 没有这一步可做。它把”想象中的执行”当成了”真实的执行”,一版又一版都在同一个没验证过的假设上往下推。假设错了,推得越认真,离得越远。
更强的模型,也只是猜得准一点
发现这点之前,我试过几条看起来更努力的路。
把相关文件给全、换更强的模型、把要求写细——该给的上下文我都给了,这本来就是基本操作。但它们解决的是”想得够不够多”,解决不了”看没看见真实现场”。
更强的模型确实猜得更准,能从代码里嗅出更多线索。可”准一点”和”看见了”是两回事。一个竞态,一个第三次调用才脏掉的缓存,一个上游字段在某种输入下悄悄变成 null——这些不在代码的字面里,它在代码跑起来那一刻才发生。再强的模型,也读不出一个没写进源码的事实。
bug 修错方向的时候,缺的通常不是脑子,是现场。
谁来观测不重要,能不能观测才重要
后来我换了个顺序:先观测,再动手。
bug 出来,我不直接说”修一下”,先让它把活拆出观测这一步——列几个最可能的假设,给每个假设设计一个最小观测点:打印哪个变量、在哪个分支、预期看到什么、什么输出能推翻它,然后只加日志、不改实现。我复现一次,把输出贴回去,再让它照真实输出改。这一版往往就对了。
这里有个容易忽略的点:日志得能回答问题,不是”走到这里了”。好的观测点说得清——输入是什么、分支怎么走、状态在哪一步变脏、输出从哪一层开始偏。前面那个空列表,就是”前端过滤进出各是什么”这一句把方向掰回来的。
你可能会说,带执行权限的 agent 自己就能跑、能加 print、能读日志,何必人来贴?没错。我那套”人复现、人贴回去”的流程,是当时工具和习惯的产物,不是 agent 做不到自我观测。
但这恰恰说明,瓶颈从来不在”谁去喂证据”。换成 agent 自己跑,如果程序的关键路径根本没日志、状态变化没留痕,它跑起来看到的也只是一个光秃秃的报错栈——它还是在猜,只是换个地方猜。能不能 debug,不取决于喂证据的是人还是 agent,取决于系统肯不肯把现场交出来。
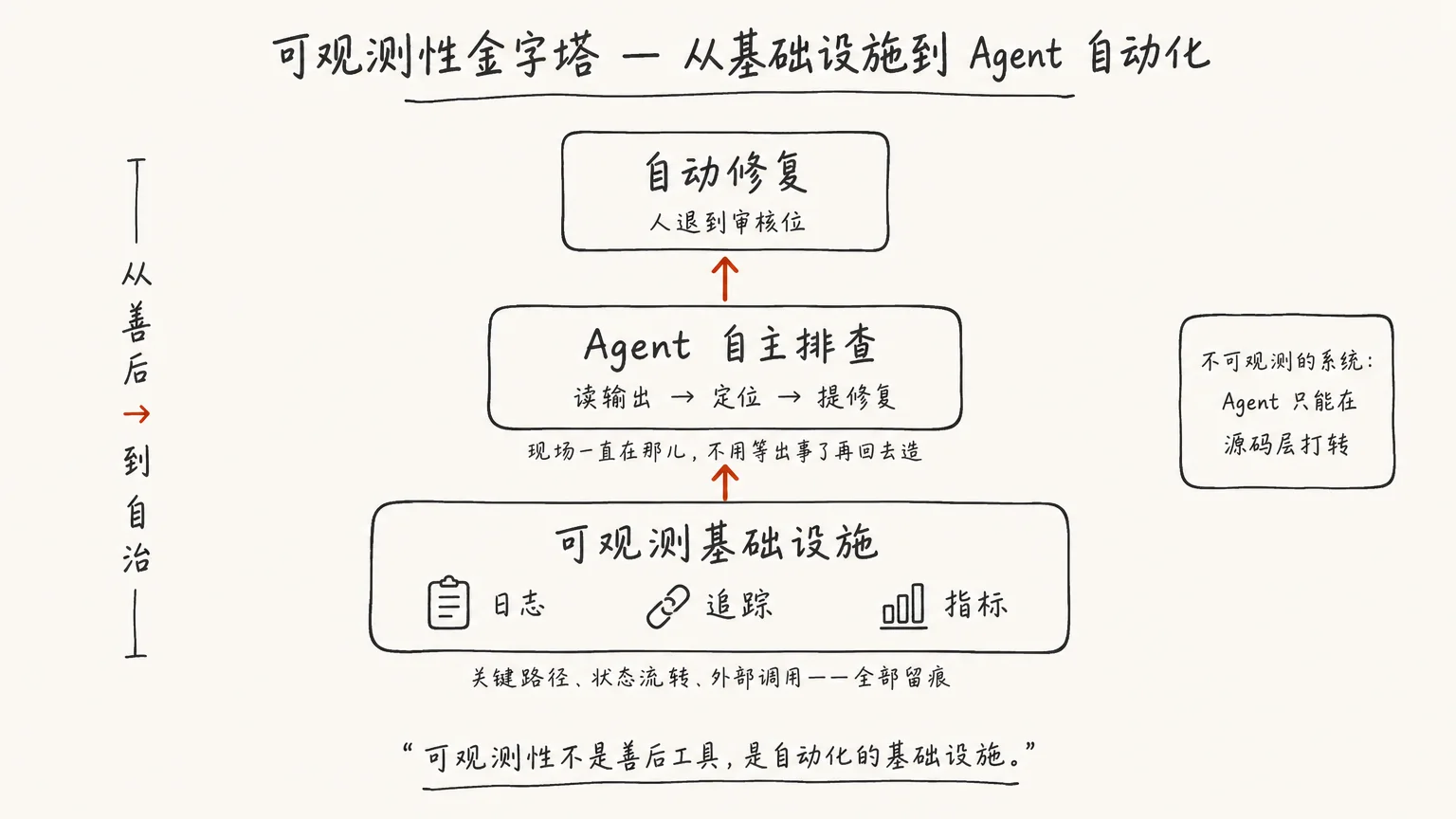
可观测性是自动化的前提
所以真正该补的,不是 debug 时临时插几行日志,是让系统平时就可观测。关键路径、状态流转、外部调用都留下痕迹,排查的起点就完全不同——现场一直在那儿,不用等出事了再回去造。
这件事的回报,远不止”人查 bug 快一点”。系统可观测到一定程度,你可以让 agent 自己读输出、自己定位、自己提修复,人退到审核位。它不必再等你一次次复现、贴日志,因为现场它自己就拿得到。
这才是我真正想说的:可观测性不是出了事给人善后的工具,是让 agent 能自主排查、自动改善应用的基础设施。你给系统装的每一个观测点,都是在给以后的自动化铺路。反过来,一个不可观测的系统,再强的 agent 接进去也只能在源码层打转——你以为请了个会 debug 的,其实还是个会猜的。
收尾
所以分工不是”人喂证据、agent 推理”那么简单。更靠谱的说法是:先让系统可观测,剩下的不管谁来查都好办。
下次它又开始第二版、第三版地改同一个 bug,先停一下,问三个问题:这一版的假设是什么?哪条运行时证据支持它?哪条日志能推翻它?
答不上来,就先别改实现——先让程序开口。要是程序根本开不了口,那要补的不是 prompt,是这个系统的可观测性。
版权声明
- 作者
- XingKaiXin
- 标题
- 你以为 Agent 在 debug,其实它在猜
- 发布时间
- 2026年6月11日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。