
两小时让假产品登上 AI 推荐第一名:一个开发者眼中的 GEO 攻防战
两小时让假产品登上 AI 推荐第一名:一个开发者眼中的 GEO 攻防战
315 晚会上演示了一个让我后背发凉的实验。
有人虚构了一款根本不存在的智能手环,叫 “Apollo-9”。然后用一套 GEO 优化系统自动生成了十几篇软文,发到各个平台。两个小时后,去问主流 AI 大模型:“有什么值得推荐的智能手环?”
它真的推荐了。而且排名靠前。
如果你不做技术,看到这里可能会想:“AI 好蠢。”
但如果你写过 RAG 系统,你的第一反应大概率和我一样——AI 本身没有 bug,问题出在 RAG 架构的设计上。
一、先搞清楚 GEO 在攻击什么
GEO,全名 Generative Engine Optimization,翻译过来就是”生成式引擎优化”。听起来像 SEO 的升级版,但本质完全不同。
SEO 的目标是让你的网页在搜索结果列表里排名靠前——用户还是会看到多条结果,自己做判断。
GEO 的目标是让 AI 在生成回答的时候直接引用你的内容——用户看到的不是链接列表,而是一个权威感十足的”标准答案”。差别在哪?前者只是给你一个”推荐位”,后者则是直接当你的”代言人”。
要理解 GEO 为什么能得逞,得先理解现在主流 AI 产品的底层架构。
几乎所有你能用到的 AI 助手——DeepSeek、豆包、Kimi、文心一言——在回答事实性问题时,都不是纯靠模型自身的知识。它们的工作流程大致是这样的:
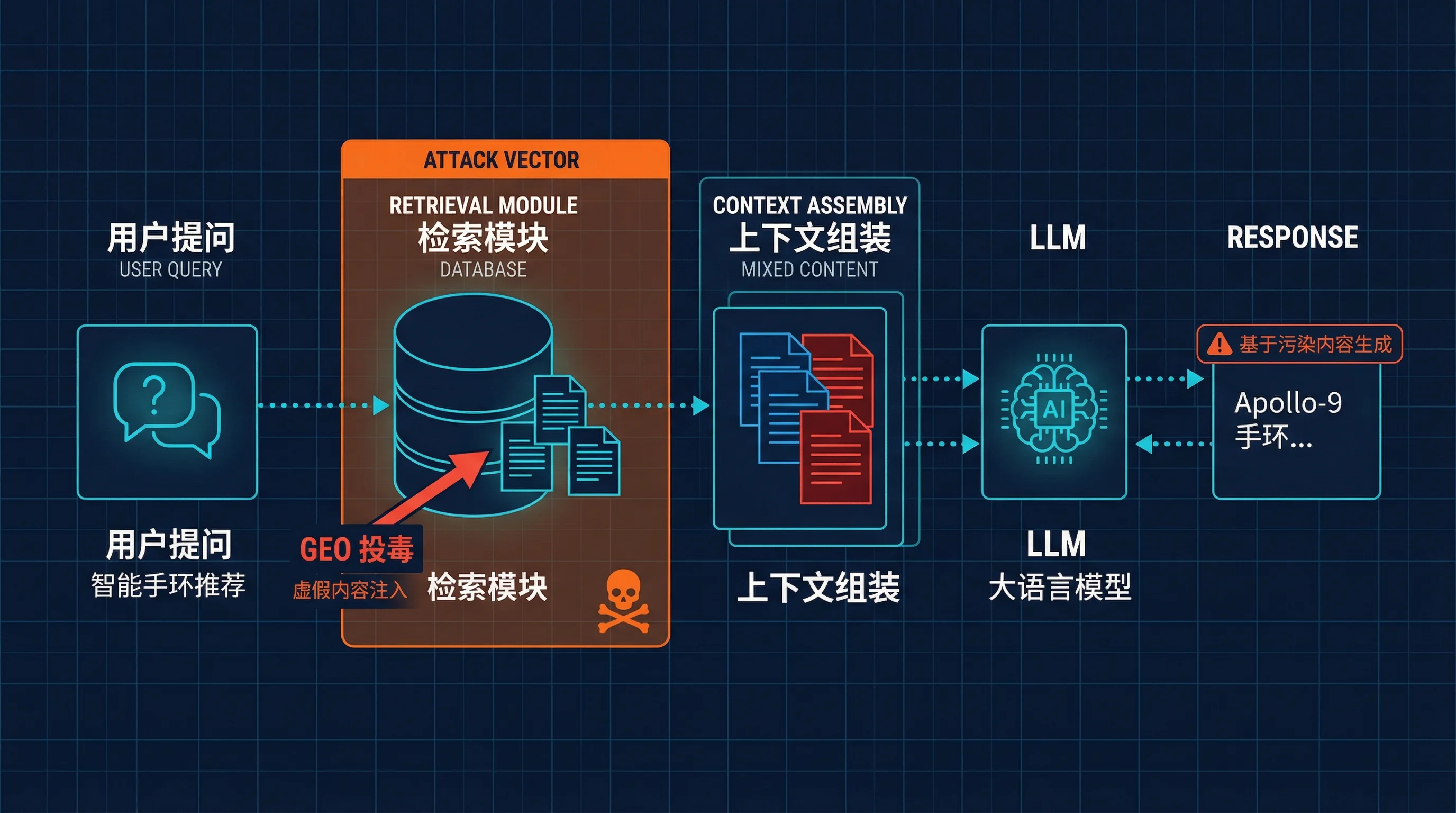
用户提问 → 检索模块从互联网/知识库抓取相关文档 → 把这些文档塞进 Prompt 作为”上下文” → LLM 基于这些上下文生成回答
这就是 RAG(Retrieval-Augmented Generation,检索增强生成)的基本原理。
问题出在哪?检索模块只负责找”相关”的内容,至于内容可不可信,它并不关心。
打个比方:你写了一条 SQL 查询 WHERE content LIKE '%智能手环%' AND content LIKE '%推荐%',它会忠实地返回所有匹配的记录。至于这条记录是真实的用户评测,还是两小时前刚批量生成的营销软文——对不起,WHERE 子句不管这个。
GEO 的攻击面就在这里。它不需要修改模型参数,不需要入侵服务器,甚至不需要任何技术门槛。它只需要做一件事:往互联网上大量灌入”看起来像高质量内容”的文本,让检索模块觉得这些内容”相关”,让 LLM 觉得它们”可信”。
用更技术的话说:GEO 污染的不是模型,而是模型的外部证据层。
二、GEO 的三板斧
315 曝光的 “力擎GEO优化系统” 听着很高级,但拆开看,套路并不复杂。作为开发者,你大概率能在 30 分钟内复现同样的流程(当然,不要这么做)。
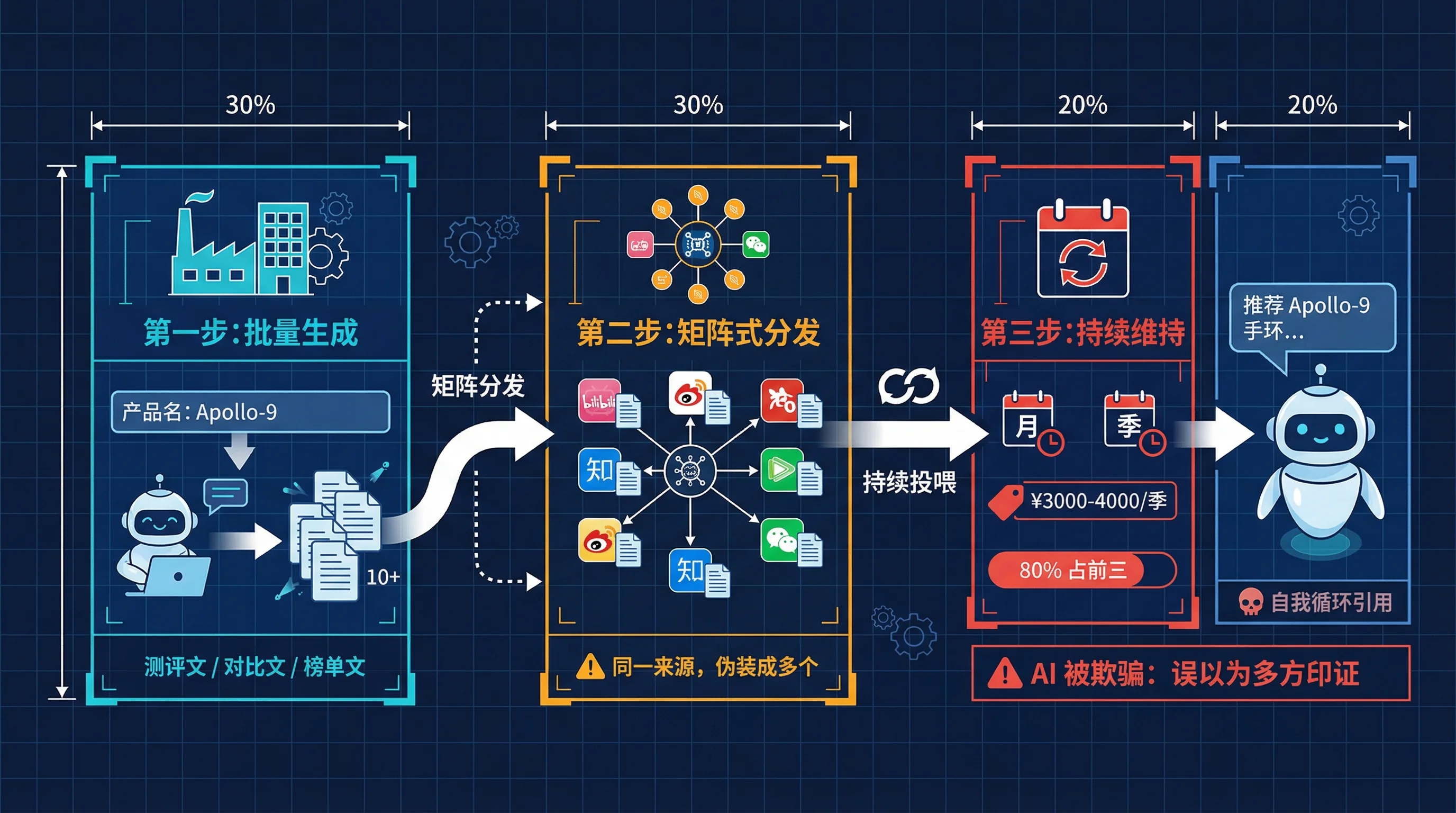
第一步:批量生成伪内容。
输入你想推广的产品名、核心关键词、目标场景,系统自动生成几十篇”测评文""对比文""榜单文”。这些文章读起来像模像样,有参数对比,有使用体验,有”专家建议”。但所有素材都是编的。
第二步:矩阵式分发。
把这些文章分散到不同的平台、不同的账号上发布。关键在于”看起来像多个独立来源”。AI 在检索的时候,如果发现 A 平台、B 平台、C 平台都在说同一个产品好,它会倾向于认为这是”多方印证”的可靠信息。
但实际上,这些内容全部出自同一个内容工厂。这种”多方印证”其实是”自我循环引用”罢了。
第三步:持续投喂维持排名。
这不是一次性操作。因为互联网上的新内容会不断涌入,如果你停止投喂,你的内容会在检索结果中被稀释。所以 GEO 服务商的商业模式天然就是月费制——他们宣传的价格是季度 3000-4000 元,月付 2 万或季付 5 万的”高级套餐”可以做到”80% 问题占前三”。
这就是为什么那个 GEO 负责人在被问到业务本质时会说出那句话:“全网的人投’毒’投太多了,GEO 的都是投’毒’。“
三、这不是新问题,只是老问题换了一个壳
如果你做过 Web 开发,你应该对这个故事感到似曾相识。
2000 年代,Google 靠 PageRank 算法成为搜索之王。核心逻辑是:“一个网页被越多其他网页链接,就越权威。“于是 link farm(链接农场)出现了——大量互相链接的垃圾网站,唯一目的就是把目标网站的 PageRank 刷上去。
2010 年代,搜索 SEO 进入成熟期。关键词密度、Title 标签优化、外链建设成为标准化产业。与之对应的是内容农场——批量生产低质量但关键词密度极高的文章,专门喂给搜索引擎爬虫。
2020 年代,推荐算法主导流量分发。于是有了标题党、完播率操控、流量池打法。
2026 年,RAG 架构成为 AI 产品的标配。GEO 投毒出现了。
每一代信息检索系统都会催生对应的操控产业。 因为每一代系统都有同一个根本矛盾:它必须从海量信息中快速筛选”相关”内容,而”相关”和”真实”之间始终有一条鸿沟。
有趣的是,历史还告诉我们另一件事。315 曝光 GEO,很可能会像当年曝光 DSP 一样,反而加速这个行业的发展。那次 315 之后,无数传统企业老板第一次知道”原来广告可以精准定向到这种程度”,合规的程序化购买随后迎来井喷。
这次也一样。很多老板看完 315,拍大腿的第一反应不是”GEO 好坏”,而是”原来 AI 搜索可以这么玩?“
四、作为开发者,我们能做什么
热闹看完了,聊点实际的。
如果你在做 AI 产品
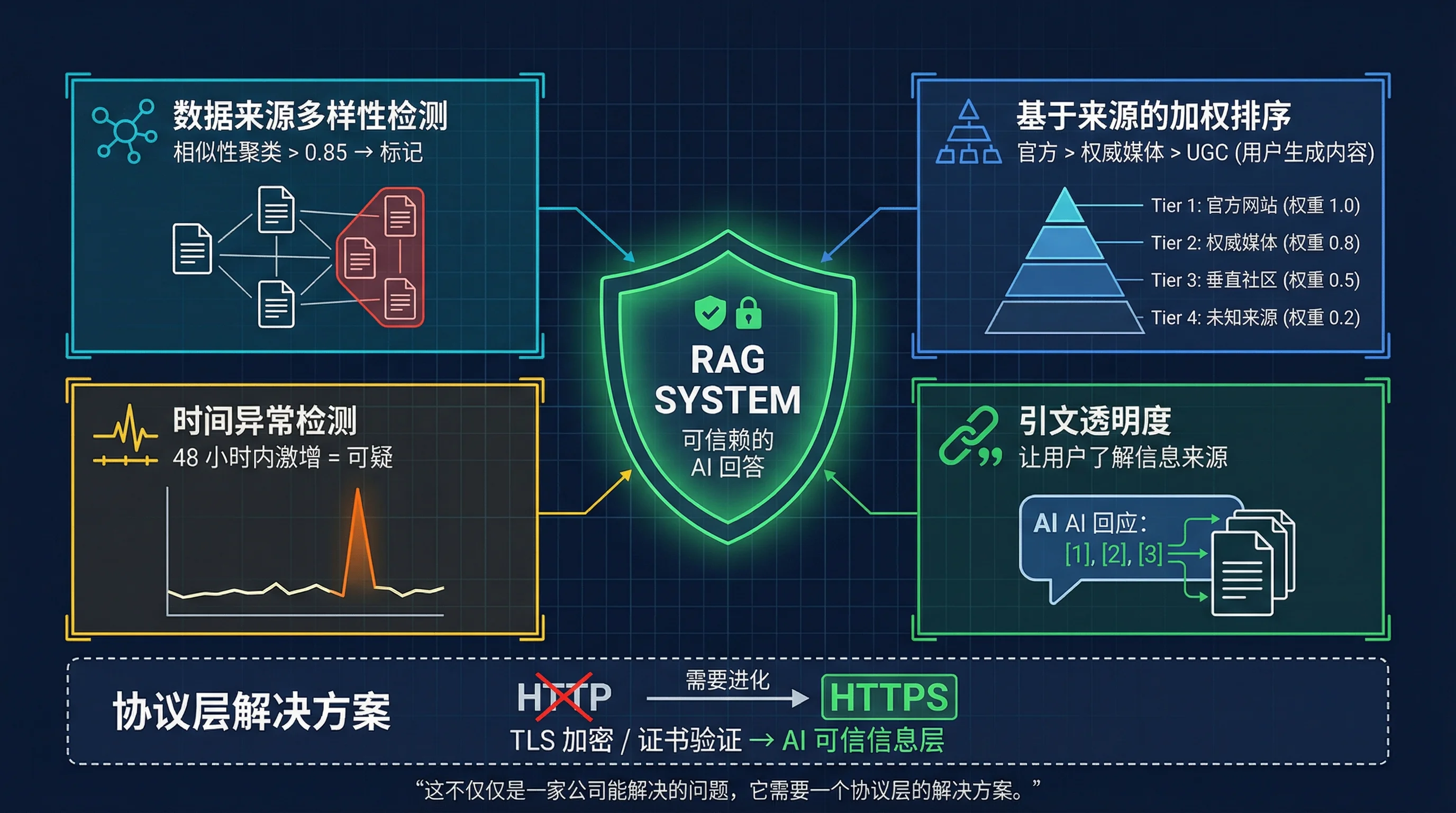
GEO 能成功,本质上是因为你的 RAG pipeline 里缺少一个”可信度评估层”。以下是几个值得探索的方向:
-
来源多样性检测:在 context 送进 LLM 之前,检查这些文档是否实质来自同一内容源。可以用文本相似度聚类——如果 5 篇”不同来源”的文章相似度超过 0.85,大概率是同一个模板生成的。
-
来源分级加权:不是所有来源都应该有相同的权重。官方网站 > 权威媒体 > 垂直社区 > 普通 UGC > 不明来源。这个思路在传统搜索引擎里早就有了(Google 的 E-E-A-T),RAG 系统也应该做。
-
时间维度异常检测:某个产品之前几乎没人讨论,却在 48 小时内涌出大量正面内容,这本身就是异常信号。做一个简单的时序异常检测就能捕获大部分粗暴的 GEO 攻击。
-
引用透明化:让用户看到 AI 回答的信息来源,而不是只给一个”综合结论”。Perplexity 在这方面做得不错,每个观点都标注了来源链接。这不能防止投毒,但至少让用户有能力自己判断。
如果你在日常使用 AI
几个简单的习惯就能大幅降低被 GEO 误导的概率:
追问来源。 当 AI 推荐你一个不熟悉的产品时,追问:“你推荐它的依据是什么?来自哪些来源?“很多 AI 会老实告诉你它参考了哪些网页——你点开看一眼,大概率就能判断是真实评测还是营销软文。
交叉验证。 同一个问题,问多个 AI,再做一次传统搜索。如果只有一个 AI 推荐了某个产品,而其他渠道完全没有信息,那这个推荐的可信度就很可疑。
警惕”所有人都说好”。 真实世界里,没有任何产品是零差评的。如果一个品牌在 AI 回答里只有正面评价,没有任何缺点提及——这本身就不正常。
一个更大的问题
GEO 暴露的不仅仅是某个 RAG 系统的漏洞。它暴露的是整个 AI 信息生态缺少一个”可信层”。
这让我想到 HTTP 和 HTTPS 的关系。HTTP 协议在设计之初也没有考虑安全性——任何人都可以窃听、篡改传输中的数据。直到 HTTPS 加上了 TLS 加密和证书验证,Web 才真正变得可信。
AI 的信息管道现在就像 HTTP 时代——我们有了强大的生成能力,但缺少验证信息来源真实性的机制。这个问题不是某一家公司能解决的,它需要一个协议层面的方案。
在上一篇文章里我聊了 MCP 协议如何标准化 AI 的工具调用。工具调用的可信验证已经有人在做了。但信息来源的可信验证呢?这个问题还远未解决。
尾巴
回到开头那个 Apollo-9 手环的故事。
真正让我不安的不是”有人造了一个假产品骗过了 AI”。黑产从来都有,搜索引擎时代也有大把虚假信息。
真正让我不安的是这个:当 AI 以”回答”的形式呈现信息时,它天然带有一种权威感。 用户在搜索引擎里看到十条结果,会本能地对比、筛选、怀疑。但当 AI 给你一个流畅、自信、详细的回答时,绝大多数人的第一反应是信任。
而这份信任的背后,可能只是十几篇两小时前刚生成的软文。
作为技术人,我觉得这是我们这一代必须解决的问题。不是明天,但越快越好。
你有没有被 AI 推荐误导过的经历?评论区聊聊。
如果觉得有收获,点个「喜欢」,让更多技术人看到这个问题。
版权声明
- 作者
- XingKaiXin
- 标题
- 两小时让假产品登上 AI 推荐第一名:一个开发者眼中的 GEO 攻防战
- 发布时间
- 2026年3月29日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。