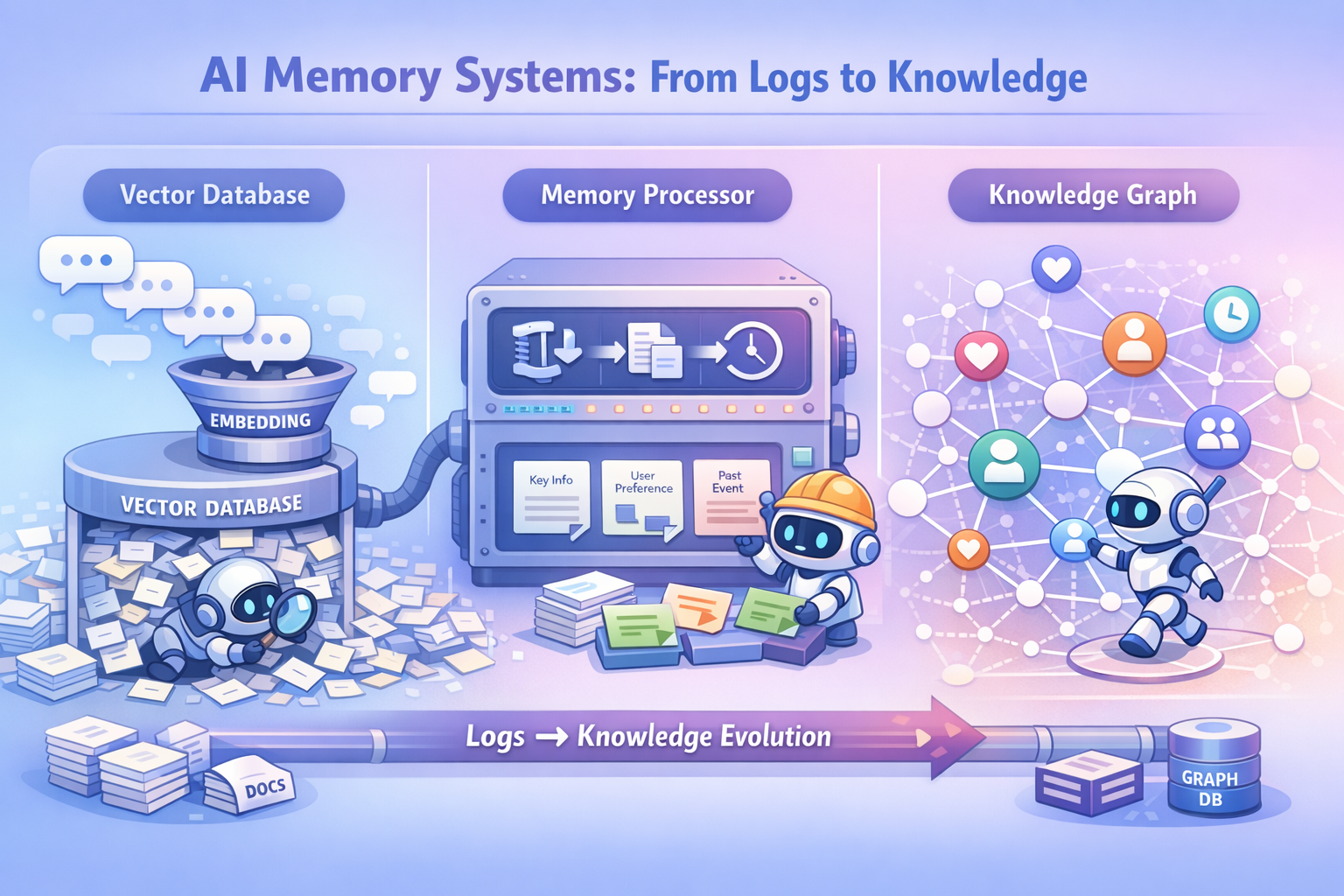
AI 记忆系统构建:从日志检索到知识演化
回顾 2025 年,这是我在持续精进的同时,有意识拓展认知边界的一年。 工作重心从上半年偏向数据基础设施与底层建设,逐步过渡到下半年对流程、规范以及复杂项目整体推进能力的打磨。与此同时,我也刻意让个人技术路径不局限于单一纵深,而是在系统性能、数据模型、AI 与跨学科知识之间形成交叉。
这一年让我更加确认:长期价值并不来自技能数量的叠加,而来自抽象能力与判断力的积累。
AI 记忆系统构建:从日志检索到知识演化
自从 ChatGPT 推出记忆功能以来,很多用户第一次体验到了”被记住”的感觉。你告诉它自己喜欢日式料理,几周后它居然主动推荐附近的寿司店——这种细微的变化,让 AI 助手从冰冷的工具变成了有”记忆”的伙伴。
但在 Agent 开发领域,这种体验依然稀缺。今天你告诉编码助手”我们项目用驼峰命名法”,明天它可能就忘得一干二净。开发者们不得不反复在提示词里堆砌各种上下文规则,结果提示词越来越长,维护越来越难,遗忘却越来越频繁。
记忆不是提示词的堆砌,而是一种系统能力。这篇文章我想聊聊:如果我们想让 AI 真正拥有长期记忆,到底需要解决哪些核心问题?
Vector Store 的天花板
现在大多数 AI 记忆方案都遵循类似的模式:把对话内容转换成向量,存入向量数据库,需要时通过相似度检索召回相关记忆。这套架构简单直观,也确实能解决一部分问题。
但说实话,它更像是一个可检索的日志系统,而不是真正的记忆。
想想人类大脑是怎么工作的。你不会把过去二十年的每一天都原封不动地存下来,而是会不断压缩、提炼、更新。上个月吃了什么早餐可能早已模糊,但小学时学会骑自行车的经历却清晰如初。记忆是有选择性的——它会演化、会冲突、也需要整理。
Vector Store 做不到这些。它只是忠实地保存每一条记录,然后在你查询时返回最相似的那几条。这解决了”找到相关信息”的问题,却没有解决”如何管理知识”的问题。
真正的记忆系统需要面对三个核心挑战。
记忆压缩:从日志到知识
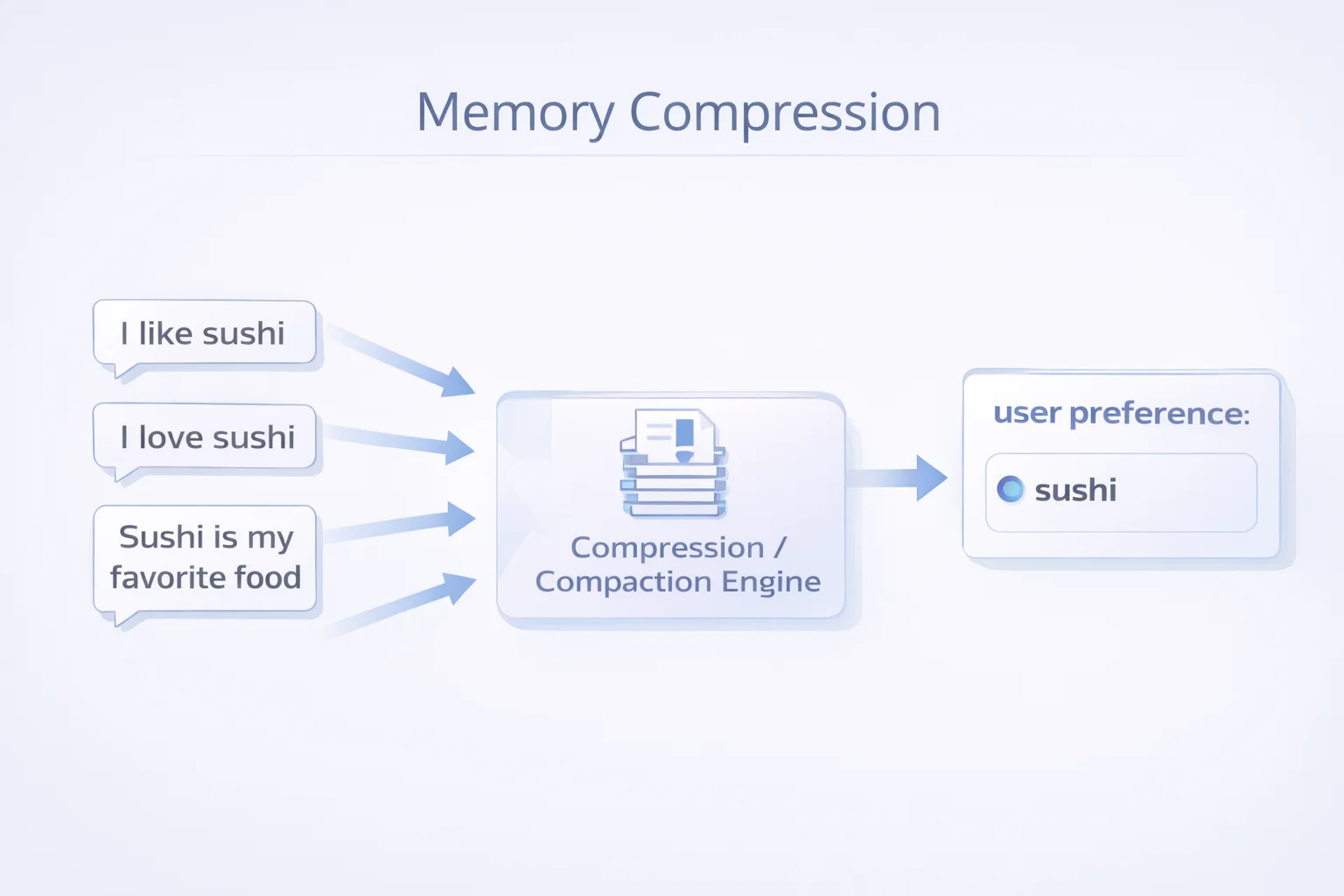
记忆会无限增长。如果系统把每一次对话都原样保存,很快就会被信息淹没。
举个例子,用户可能多次表达类似的偏好:“我喜欢寿司”、“我爱吃寿司”、“寿司是我最喜欢的食物”。一个简单的系统会保存三条甚至更多记忆,但真正有价值的其实只有一条:“用户喜欢寿司”。
这里需要的不是简单的去重,而是将大量原始交互压缩为更高层的知识表示——有点像数据库中的 LSM-tree compaction,把原始日志压缩成更高层的状态快照。AI 记忆也需要类似的机制:从原始交互到结构化知识。
但实现起来远比数据库复杂。
首先是抽象层级的问题。假设系统观察到用户喜欢寿司、拉面、披萨,它应该总结出”用户喜欢食物”还是”用户喜欢日本料理”?抽象得太高会丢失信息,太低又达不到压缩效果。如何自动决定合适的抽象层级,至今没有标准答案。
然后是触发时机的选择。定期压缩容易错过紧急信息,基于相似度触发又可能让系统过于敏感。就像你不会每隔固定时间就整理一次房间,也不会一有东西乱了就马上收拾。
最棘手的是避免信息丢失。假设用户说”我喜欢寿司”,又说”我对贝类过敏”。如果系统草率地压缩成”用户喜欢海鲜”,就会埋下安全隐患。记忆压缩必须非常谨慎,因为一旦信息丢失,可能再也找不回来。
记忆演化:当事实发生变化
人类的记忆不是静态的,它会随时间不断更新。2023 年你住在纽约,2024 年搬到了西雅图。一个好的记忆系统应该能理解:纽约的信息已经过期,西雅图才是当前状态。
但 Vector Store 做不到这一点。它只是简单地追加新记录,旧记录永远保留。当你查询时,系统可能同时返回”用户住在纽约”和”用户住在西雅图”,却不知道哪个才是正确的。
从这个角度看,Vector store 更像一个日志系统,而真正的记忆系统需要一个状态机。
事实更新是一个典型场景。用户以前说最爱 Python,后来改学 Rust。系统应该更新旧记忆,而不是简单地追加新记忆。但在向量空间里,“更新”本身就是一个模糊的概念。
时间维度同样关键。一个好的记忆系统应该记录信息的有效时间窗口:“用户 2019-2024 年住在纽约,2024 年起住在西雅图”。这样系统才能在特定时间上下文中做出正确推断。
这自然引出了长期记忆与短期记忆的区分。“用户喜欢寿司”可能是长期稳定的偏好,但”用户正在东京旅行”只是临时状态。认知科学里把这分为情景记忆和语义记忆,AI 记忆系统也需要类似的分层结构。
记忆冲突:当信息相互矛盾
这是最困难的问题——记忆很可能互相矛盾。
想象一下,记忆 A 说”用户是素食者”,记忆 B 却说”用户喜欢牛排”。系统必须决定:哪一个才是正确的?
冲突的来源多种多样。可能是用户行为真的发生了变化,从素食者变成了杂食者。可能是用户表达不一致,今天说讨厌 Python,明天又说它很棒。也可能是 LLM 的推断出了错,把语境中的玩笑当成了真实偏好。
解决冲突的策略各有优劣。
时间优先是最直观的:最新信息覆盖旧信息。2023 年是素食者,2024 年开始吃肉,就采用 2024 年的状态。但这并不总是正确,比如用户可能只是在尝试新的饮食方式,并非彻底放弃素食。
置信度机制也很有用。来自用户明确陈述的记忆可以标记为高置信度,LLM 推断的标记为低置信度。冲突时优先选择高置信度记忆。但置信度本身如何量化,又是一个难题。
来源追踪同样重要。记录每条记忆是来自用户直接陈述、LLM 推断还是系统预设,冲突时优先采信用户的话。但这会增加系统的复杂度。
还有一种思路是保留多版本记忆:“用户 2018-2023 年是素食者,2023 年后开始吃肉”。这样系统就能在不同时间上下文中使用不同的记忆版本。当然,这也意味着存储成本和管理复杂度的上升。
从开发者视角看记忆
对于每天与 AI 编码助手打交道的开发者来说,这些问题都不是抽象的学术讨论。
在同一个项目内,记忆意味着代码风格的一致性。你告诉助手”我们用驼峰命名法”、“组件文件放在 components 目录下”、“优先使用函数式组件”,希望它能记住这些规则并在后续对话中自动遵循。如果它每次都要重新学习,开发效率就会大打折扣。
跨项目时,记忆涉及个人编码习惯的迁移。你喜欢用某些特定的设计模式,对类型安全有偏执,习惯特定的错误处理方式。如果 AI 能记住这些偏好,在新项目中就能更快进入状态。
与提示词管理相比,真正的记忆系统优势明显。提示词需要手动维护,容易遗漏,长度有限。而记忆系统可以自动更新,按需检索,理论上可以无限扩展。更重要的是,记忆是结构化的,可以被推理、被更新、被解决冲突,而提示词只是一段文本。
更完整的记忆架构
一个成熟的 AI 记忆系统可能需要这样的架构:
原始交互首先经过记忆提取层,由 LLM 识别出值得保存的信息。然后进入结构化存储,在这里经历压缩、演化和冲突解决的处理流程。最后被检索层按需召回。
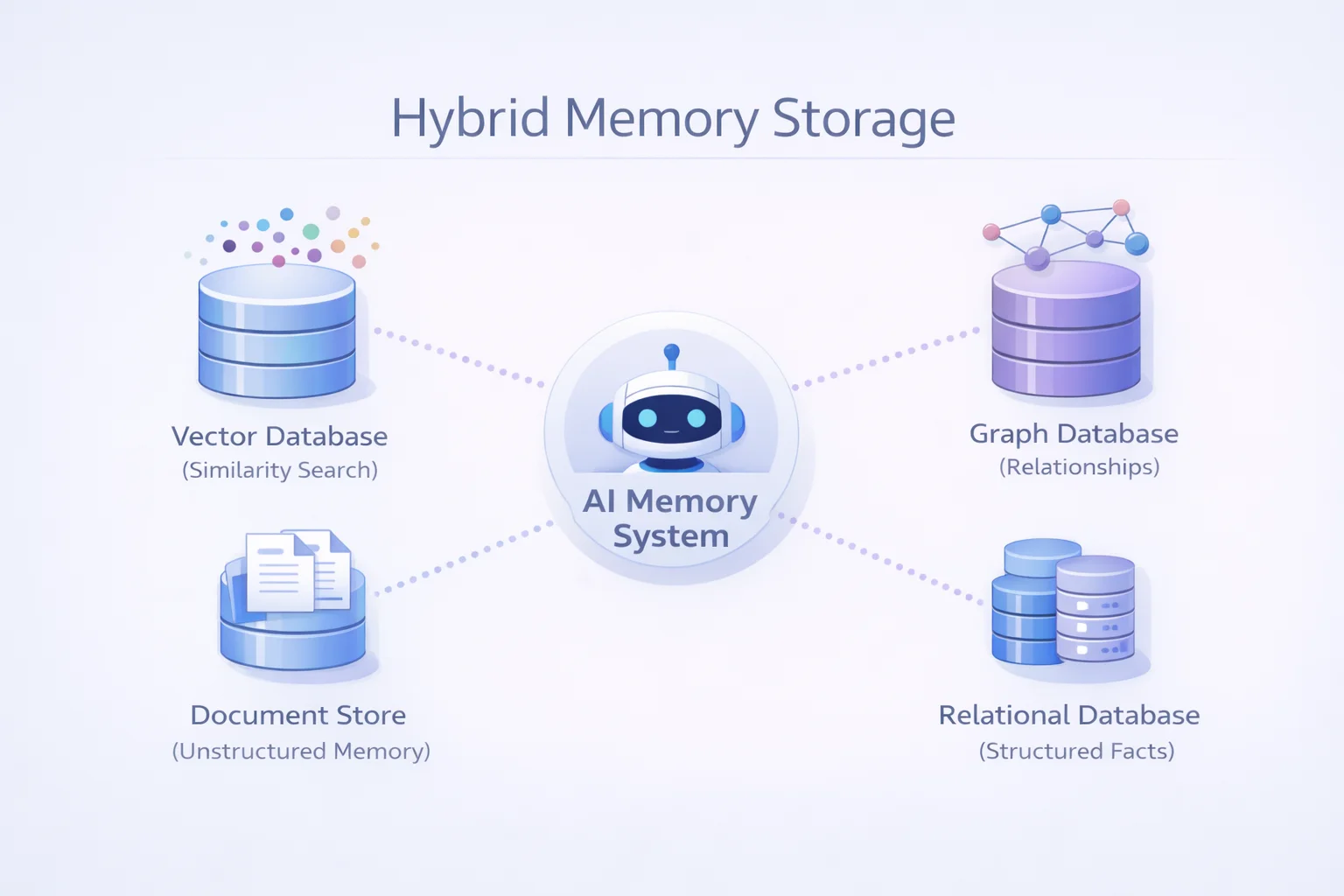
存储层的选择也很关键。Vector Database 擅长相似度检索,但不擅长表示关系。Graph Database 可以很好地建模实体间的关系。Document Store 适合存储非结构化记忆。Relational Database 则擅长处理结构化属性和约束。真正的记忆系统很可能需要多种存储的组合。
工作流层面,系统需要定期运行 compaction 来压缩冗余记忆,持续监控和更新演化中的记忆,并在检测到冲突时触发解决机制。这不是一次性的批处理,而是持续运行的后台进程。
记忆的本质是知识管理
回头看这三个挑战,它们其实都指向同一个洞察:AI 记忆不是一个检索问题,而是一个知识管理问题。
向量数据库解决的是相似度检索,而记忆系统需要解决的是知识表示、演化和冲突解决。这更像是在构建一个持续演化的知识系统,而不仅仅是一个嵌入向量索引。
Mem0 等项目已经开始探索记忆提取、评分和更新机制,意识到 Memory 不等于 Retrieval。但整体上,这还是第一代 AI 记忆系统。
真正成熟的 AI 记忆,需要能够压缩经验、更新事实、解决矛盾。核心问题其实只有一个:我们应该如何表示”记忆”本身。
当这个问题有了更好的答案,AI 助手或许就能真正记住你——不是像搜索日志那样找到相关记录,而是像朋友那样,记得你喜欢什么、经历过什么、此刻需要什么。那将是一个完全不同的交互时代。
版权声明
- 作者
- XingKaiXin
- 标题
- AI 记忆系统构建:从日志检索到知识演化
- 发布时间
- 2026年3月16日
本作品采用 CC BY-NC-ND 4.0 DEED 许可。